научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 11, ноябрь 2012
DOI: 10.7463/1112.0500433
УДК 519.6
Россия, МГТУ им. Н.Э.Баумана
Введение
Системы голосовой идентификации личности (СГИЛ) интенсивно развиваются в последние годы. Стимулом для развития СГИЛ является их востребованность в таких областях, как криминалистический учет и биометрический поиск, голосовая верификация водителя и пассажиров, разграничение прав доступа к информации с помощью голосовой биометрии и т. д. [1]. Важным достоинством СГИЛ по сравнению с другими биометрическими системами идентификации является их дешевизна. Важно также, что современные СГИЛ по уровню надежности идентификации не уступают, а иногда и превосходят, например, системы идентификации человека по изображению [2].
Отметим близость задачи идентификации личности по голосу к задаче распознавания речи. Системы распознавания речи, например, Google Voice Search, Dragon Naturally Speaking, Voice Navigator, Microsoft Voice Command, автоматически переводят голос пользователя в текст, освобождая его руки. Эволюция систем распознавания речи привела к созданию интеллектуальных систем, позволяющих не только распознавать, но и автоматически синтезировать человеческую речь. Такие системы широко используются с целью снижения нагрузки на операторов контакт-центров и секретарей, для организации общения пользователей с голосовыми порталами и т.д.
Несмотря на уникальность голоса человека, обусловленную уникальностью строения его голосовых связок, трахеи и носовых полостей, манерой произношения звуков, расположением зубов и так далее, ни одна из СГИЛ, как и любая другая биометрическая система, не может гарантировать 100 % надежность идентификации. Основными источниками ошибок в СГИЛ являются: окружение (шум, реверберация и т.д.); особенности речи (длительность, тональность, уровень голосового усилия и т.д.); канал связи (искажения микрофона и канала передачи, погрешности кодирования аудиосигнала и т.д.) [2].
В общем случае идентификация личности по голосу требует решения большого числа разнородных задач, основными из которых являются следующие:
‑ выделение вокализованных участков аудиосигнала путем отбрасывания пауз и участков, содержащих различного рода помехи;
‑ разделение речи дикторов (задача диаризации);
‑ выделение характерных признаков голоса диктора.
Задаче выделения вокализованных участков аудиосигнала посвящено большое число работ. Известны решения этой задачи, обеспечивающие уровень ошибок, не превышающий 10 % (см., например, работу [3]).
Компоненту СГИЛ, которая решает задачу диаризации, называют детектором речевой активности (voice activity detector, VAD). Обзор основных алгоритмов, используемых в этих детекторах, приведен, например, в работе [2].
В нашей работе основное внимание уделено последней, третьей задаче выделения характерных признаков голоса (ХПГ). Вообще говоря, для выделения ХПГ можно использовать спектрально-формантный анализ, статистические характеристики основного тона голоса, параметрическое представление аудиосигнала. В последнем случае ХПГ можно искать в амплитуде и диапазоне частот звукового сигнала, а также в его спектре. Мы используем метод, предполагающий идентификацию человека по голосу на основе набора основных частот в его спектре. Обширный список публикаций, посвященных перечисленным методам, представлен в работе [4].
Набор ХПГ называем картой ХПГ. После формирования карты ХПГ данного человека возникает задача сравнения этой карты с картами ХПГ, хранящимися в базе данных СГИЛ. Оригинальность нашей работы заключается в использовании с этой целью самоорганизующейся карты Кохонена (Self-Organizing Map, SOM), которая представляет собой соревновательную нейронную сеть с обучением без учителя. Сеть преобразует входные многомерные векторы в одно- или двухмерную дискретную карту [5].
В первом разделе статьи приводим постановку задачи и общую схему предложенного метода идентификации личности по голосу. Второй раздел содержит описание программной реализации метода. В третьем разделе приведены результаты тестирования и исследования эффективности принятых алгоритмических и программных решений. В заключении сформулированы основные результаты работы и перспективы ее развития.
1. Постановка задачи и общая схема метода
Полагаем, что аудиосигнал представляет собой одномерный равноотстоящий ряд ![]() ,
, ![]() ,
, ![]() абсолютных значений громкости сигнала в диапазоне
абсолютных значений громкости сигнала в диапазоне ![]() дБ. В аудиосигнале представлены частоты голоса человека в диапазоне от 40 до 1600 Гц и длительностью
дБ. В аудиосигнале представлены частоты голоса человека в диапазоне от 40 до 1600 Гц и длительностью ![]() от нескольких секунд до нескольких минут. Аудиосигнал содержится в файле формата *.wav.
от нескольких секунд до нескольких минут. Аудиосигнал содержится в файле формата *.wav.
В общем случае идентификатор ![]() сигналов определяют [6] как оператор, сопоставляющий сигналу
сигналов определяют [6] как оператор, сопоставляющий сигналу ![]() номер класса
номер класса ![]() , к которому он относится:
, к которому он относится:
![]() .
.
Очевидной является идея использования величин ![]() в качестве
в качестве ![]() -вектора признаков сигнала. Однако в силу высокой размерности так определенного вектора (длина сигналов может достигать нескольких тысяч отсчетов), а также различной длины сигналов, данную идею на практике не используют. Подавляющее большинство методов идентификации временных рядов предполагает переход с помощью некоторого оператора
-вектора признаков сигнала. Однако в силу высокой размерности так определенного вектора (длина сигналов может достигать нескольких тысяч отсчетов), а также различной длины сигналов, данную идею на практике не используют. Подавляющее большинство методов идентификации временных рядов предполагает переход с помощью некоторого оператора ![]() от ряда
от ряда ![]() к некоторому вектору характерных признаков
к некоторому вектору характерных признаков ![]() этого ряда (статическому паттерну) размерности M:
этого ряда (статическому паттерну) размерности M:
![]() ,
, ![]() .
.
Таким образом, задачу идентификации временного ряда ставим как задачу поиска операторов ![]() таких, что
таких, что
![]() ,
, ![]() ,
,
![]() .
.
Система VOICE состоит из обучающей и распознающей подсистем. Первая из подсистем предназначена для формирования базы данных голосов в форме их карт ХПГ. Вторая подсистема призвана обеспечить поиск в указанной базе заданного числа ранжированных голосов, в некотором смысле наиболее близких к анализируемому голосу. Основу обеих подсистем составляет метод, обеспечивающий формирование карт ХПГ, а также сравнение этих карт (рисунок 1).

Рисунок 1 – Схема метода формирования карты ХПГ
Таким образом, формирование карты ХПГ в программной системе VOICE производим по следующей схеме.
1) Калмановская фильтрация. Зашумленный аудиосигнал ![]() с записью речи человека обрабатываем фильтром Калмана [7]. Наряду с фильтром Калмана, в вычислительной практике широко используют рекурсивные фильтры Чебышева, Бесселя, Баттерворта, эллиптические фильтры и гребенчатые фильтры [8]. Предпочтение отдано фильтру Калмана вследствие его высокой эффективности.
с записью речи человека обрабатываем фильтром Калмана [7]. Наряду с фильтром Калмана, в вычислительной практике широко используют рекурсивные фильтры Чебышева, Бесселя, Баттерворта, эллиптические фильтры и гребенчатые фильтры [8]. Предпочтение отдано фильтру Калмана вследствие его высокой эффективности.
2) Быстрое преобразование Фурье. Полученный на выходе фильтра Калмана сигнал ![]() передаем на вход быстрого преобразователя Фурье, выходом которого является спектр сигнала
передаем на вход быстрого преобразователя Фурье, выходом которого является спектр сигнала ![]() . Известной альтернативой БПФ является вейвлет-преобразование [8]. Предпочтение БПФ отдано, прежде всего, вследствие простоты его реализации и интерпретации результатов преобразования, высокой скорости вычислений. Важно также, что по своей природе голос человека представляет собой сумму ограниченного числа гармонических сигналов. Поэтому функция
. Известной альтернативой БПФ является вейвлет-преобразование [8]. Предпочтение БПФ отдано, прежде всего, вследствие простоты его реализации и интерпретации результатов преобразования, высокой скорости вычислений. Важно также, что по своей природе голос человека представляет собой сумму ограниченного числа гармонических сигналов. Поэтому функция ![]() не может содержать, например, импульсов прямоугольной или треугольной формы.
не может содержать, например, импульсов прямоугольной или треугольной формы.
3) Фильтрация методом скользящего среднего [9]. Обрабатываем спектр ![]() фильтром скользящего среднего так, чтобы в полученном спектре
фильтром скользящего среднего так, чтобы в полученном спектре ![]() присутствовал только аудиосигнал.
присутствовал только аудиосигнал.
4) Определение границ сигнала. Удаляем из аудиозаписи фрагменты, содержащие только шум (когда человек не говорил).
5) Выделение паттернов (ХПГ). Осуществляем переход от исходного пространства динамических данных к пространству многомерных статических данных. Выделение паттернов производим методами многомерной классификации.
6) Обучение карты Кохонена. Результатом обучения является карта ХПГ данной личности, позволяющая представить эти признаки в компактной и удобной для распознавания форме. Обучение самоорганизующейся карты Кохонена производим в четыре этапа до тех пор, пока не будут исчерпаны все входные векторы: инициализация сети, подвыборка, поиск максимального соответствия, коррекция весов нейронов [5].
7) Анализ характерных признаков (только в распознающей подсистеме) заключается в сравнении полученной карты ХПГ с аналогичными картами других личностей, хранящимися в базе данных системы. Если при этом обнаруживается карта ХПГ, близкая данной карте, то возвращаемся на один из предыдущих этапов обработки. В противном случае признаем карту корректной и сохраняем в базе данных под уникальным именем.
2. Программная организация системы
IDEF0-схема системы VOICE представлена на рисунке 2.
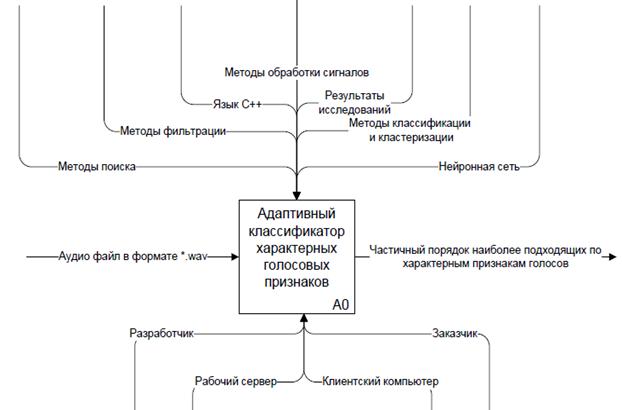
Рисунок 2 ‑ IDEF0-схема системы VOICE
Структурно система состоит из трёх модулей, которые, вообще говоря, могут выполняться на различных ЭВМ или процессорах (рисунок 3).
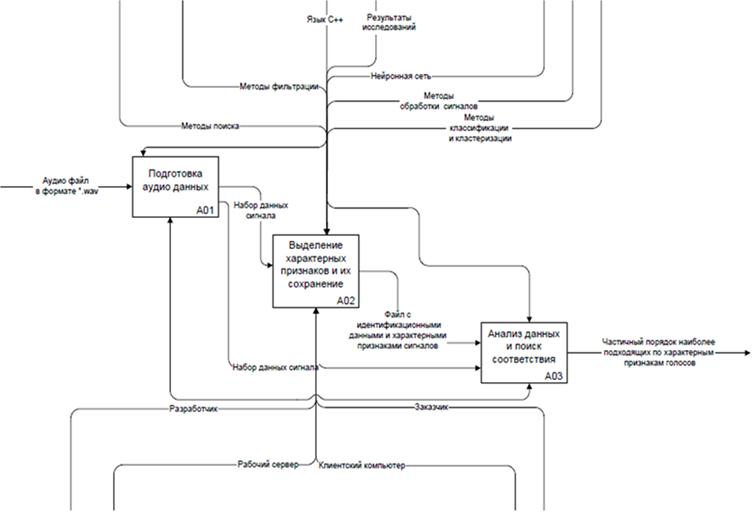
Рисунок 3 – Структура системы VOICE
Модуль А01 представляет собой утилиту подготовки исходных аудиоданных. На вход модуль принимает от двух до трёх параметров:
imperial@linux-ckfc:~/voice/audio_prep> ./convert
./convertinput_file.wavout_putfile.txt <max_length (= wav_len)>
Первые два параметра являются обязательными и указывают на аудиофайл в формате *.wav и имя текстового файла, в который будет записана информация об обрабатываемом звуковом сигнале. Третий параметр позволяет менять длину подлежащего обработке сигнала в том случае, когда нас интересуют данные не из всего аудиофайла, а только из его некоторой части. При отсутствии третьего параметра вся информация из аудиофайла поступает в результирующий текстовый файл. Пример результата работы модуля представлен ниже.
imperial@linux-ckfc:~/voice/audio_prep>time ./convert roland.wav roland.txt
Sample rate: 44100
Channels: 1
Bits per sample: 16
Duration: 00:18
subchunk2Size 1611776
blockAlign 2
real 0m1.878s
user 0m0.052s
sys 0m0.852s
Пример показывает, что перекодирование 1611776 дискретных значений заняло на тестовой виртуальной машине в системе Open SUSE менее двух секунд.
Структура указанного выше текстового файла имеет следующий вид:
imperial@linux-ckfc:~/voice/samples> head -n 5 alex_full.txt
length=454656
time=10.3097
0 -185
2.26757e-05 -193
4.53515e-05 -75
Здесь length – число дискретных значений во временном ряде, time ‑ полное время аудиозаписи. Далее следуют пары ![]() ,
, ![]()
Модуль А02 предназначен для построения базы данных ХПГ. На вход модуля требуется подать текстовый файл, полученный в результате работы модуля А01:
imperial@linux-ckfc:~/voice/execute> ./buildbase
Preparing data
Error: wrong parameter
./buildbasefile.txt
Текстовые сообщения, фиксирующие этапы работы модуля А02, выводятся в стандартный поток вывода. В приведенном выше примере таким является сообщение Preparingdata, свидетельствующее о том, что модуль приступил к подготовке данных. Ошибки в ходе выполнения модуля выводятся в стандартный поток вывода ошибок. Если ошибка является критической, то модуль завершается аварийно. Пример такой ошибки представлен выше (отсутствие входного текстового файла).
При нормальном завершении модуля выводятся сообщения обо всех пройденных этапах обработки данных, а также сообщение о добавлении записи в базу данных системы. Далее выводится время, затраченное на выполнение всех этапов обработки, освобождается оперативная память и завершается выполнение модуля:
imperial@linux-ckfc:~/voice/execute>time ./buildbase bruce.txt
Preparing data
Processing FFT
Processing filter
Processing FFT inverse
Teaching SOM
E=4.6229
Working with database
7 records in database.txt
Preparing result.html
-----------------------------------
Work time in ms: 5519
real 0m5.549s
user 0m1.540s
sys 0m3.432s
Характерные признаки сигнала модуль записывает в файл database.txt. Время работы модулей А02, А03 в значительной степени зависит от большого числа свободных параметров метода. В приведенном выше примере полное время работы модуля составило около пяти с половиной секунд.
Модуль А03 выполняет сравнение карты ХПГ, соответствующей аудиосигналу из файла database.txt, с картами, хранящимися в базе данных модуля. В качестве входного модуль А03 также использует выходной текстовый файл модуля А01.
Правила вывода информации в стандартные потоки вывода и ошибок в модуле А03 соответствуют аналогичным правилам модуля А02. В качестве результата поиска выводятся идентификаторы тех записей базы данных, которые обеспечивают максимальные значения используемой меры близости ХГП (в приведенном ниже примере это число равно четырем).
imperial@linux-ckfc:~/voice/execute> time ./identify alex.txt
Preparing test signal
Processing FFT for Test Signal
Processing filter for test signal
Teaching SOM
E=0.331418
Loading database.txt
Checking test signal
-----------------------------------
Classifier check result (sortted by relevance):
1) alex (id= 0) 72.00%
2) bruce (id= 1) 22.00%
3) kathy (id= 3) 4.00%
4) zarvox (id= 7) 2.00%
-----------------------------------
Preparing result.html
-----------------------------------
Work time in ms: 3995
real 0m4.024s
user 0m0.588s
sys 0m3.180s
Модули А02, А03 продуцируют также файл result.html, содержащий отчёт об их работе. Отчет включает в себя графики сигнала до и после фильтрации шумов, веса карты Кохонена и спектр сигнала. Также в файле дублируется текстовая информация, поступающая в стандартный вывод указанных модулей. Содержимое файла result.html является вспомогательным и может быть востребовано при отладке системы и интерпретации результатов ее работы. Для сокращения вычислительных затрат запись указанных графиков в файл может быть отменена.
3. Тестирование и исследование эффективности системы
Тестирование системы VOICEвыполнено по следующей схеме.
1) Двадцать человек прочли по два небольших фрагмента текста так, что длительность каждой из 40 полученных аудиозаписей составила 20-30 секунд. Аудиозаписи были получены со встроенного микрофона ноутбука в условиях зашумленности и при отключенной фильтрации шумов, которую реализует используемая операционная система.
2) Все аудиозаписи были разделены на два набора таким образом, что голос каждого из 20 дикторов присутствовал в каждом из наборов. Первый набор записей использован в качестве обучающего, а второй – в качестве тестового.
3) Тестирование считалось успешным, если человек из второго набора был однозначно идентифицирован (оказался на первом месте в числе четырех претендентов, указанных в предыдущем разделе).
Тестирование обеспечило 100 % идентификацию в указанном смысле.
3.1. Оптимизация обучения карты Кохонена. Обучение адаптивной карты Кохонена представляет собой, по сути, задачу глобальной оптимизации – найти такие веса нейронов, которые обеспечивают минимум ошибки обучения ![]() . С целью повышения вероятности локализации глобального минимума этой величины в процессе обучения используем метод мультистарта по случайным начальным весам нейронов. Обозначим число этих стартов
. С целью повышения вероятности локализации глобального минимума этой величины в процессе обучения используем метод мультистарта по случайным начальным весам нейронов. Обозначим число этих стартов ![]() .
.
Результаты исследования минимальной ошибки обучения карты Кохонена в функции числа мультистартов Nпредставлены в таблицах 1, 2, которые иллюстрируют рисунки 4, 5.
Таблица 1 ‑ Минимальная ошибка обучения карты Кохонена min (Err) в функции числа мультистартов N: этап построения базы данных
Голос | N | ||||
1 | 2 | 5 | 10 | 20 | |
alex | 5,23 | 5,08 | 4,88 | 4,80 | 4,79 |
zarvox | 16,11 | 15,68 | 14,53 | 13,47 | 13,23 |
Таблица 2 ‑ Минимальная ошибка обучения карты Кохонена min (Err) в функции числа мультистартов N: этап распознавания
Голос | N | ||||
1 | 2 | 5 | 10 | 20 | |
alex | 5,86 | 5,29 | 4,87 | 4,74 | 4,70 |
zarvox | 13,75 | 13,62 | 13,53 | 13,04 | 13,02 |
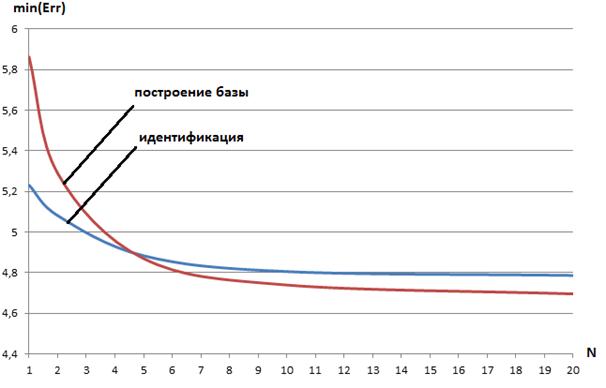
Рисунок 4 ‑ Лучший результат обучения карты Кохонена min (Err) в функции числа мультистартов N: голос alex
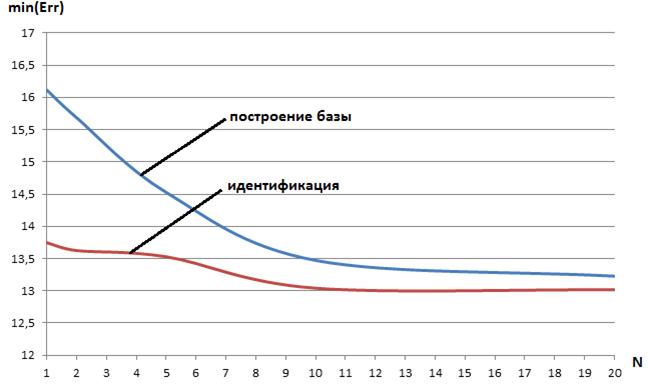
Рисунок 5 ‑ Лучший результат обучения карты Кохонена min (Err) в функции числа мультистартов N: голос zarvox
Представленные результаты показывают, во-первых, что мультистарт может значительно повысить качество обучения карты Кохонена. Во-вторых, из представленных данных следует, что, начиная примерно с 10 стартов, имеет место стагнация ошибки обучения min (Err). На этом основании в качестве умолчательного значения величины Nв системе VOICE используем значение 10.
3.2. Оптимизация числа характерных признаков. Важнейшим свободным параметром идентификатора является число характерных голосовых признаков M(равное числу нейронов карты Кохонена). В таблицах 3 ‑ 6 представлены результаты исследования зависимости временных затрат на идентификацию tи минимальной ошибки обучения карты Кохонена min (Err) в функции этой величины. Указанные таблицы иллюстрируют рисунки 6 – 9.
Таблица 3 ‑ Время идентификации t(сек) в функции числа ХПГ:
этап построения базы данных
Голос | M | ||||||
4 | 9 | 16 | 25 | 36 | 49 | 64 | |
alex | 5,82 | 7,27 | 9,28 | 11,82 | 14,89 | 19,24 | 25,87 |
zarvox | 23,33 | 33,14 | 46,68 | 64,00 | 85,49 | 116,43 | 160,30 |
Таблица 4 ‑ Минимальная ошибка обучения карты Кохонена min (Err) в функции числа ХПГ: этап построения базы данных
Голос | M | ||||||
4 | 9 | 16 | 25 | 36 | 49 | 64 | |
alex | 12,30 | 8,44 | 4,95 | 3,58 | 2,48 | 2,11 | 1,12 |
zarvox | 78,70 | 37,04 | 16,15 | 11,54 | 8,61 | 4,71 | 3,68 |
Таблица 5 ‑ Время идентификации t(сек) в функции числа ХПГ:
этап распознавания
Голос | M | ||||||
4 | 9 | 16 | 25 | 36 | 49 | 64 | |
alex | 4,51 | 5,17 | 6,06 | 7,10 | 8,86 | 10,38 | 12,92 |
zarvox | 12,06 | 16,37 | 21,97 | 29,37 | 39,34 | 51,65 | 71,65 |
Таблица 6 ‑ Минимальная ошибка обучения карты Кохонена min(Err) в функции числа ХПГ: этап идентификации
Голос | M | ||||||
4 | 9 | 16 | 25 | 36 | 49 | 64 | |
alex | 12,82 | 8,36 | 5,54 | 3,29 | 2,59 | 1,67 | 1,32 |
zarvox | 77,82 | 33,99 | 15,04 | 12,40 | 8,30 | 5,55 | 4,10 |
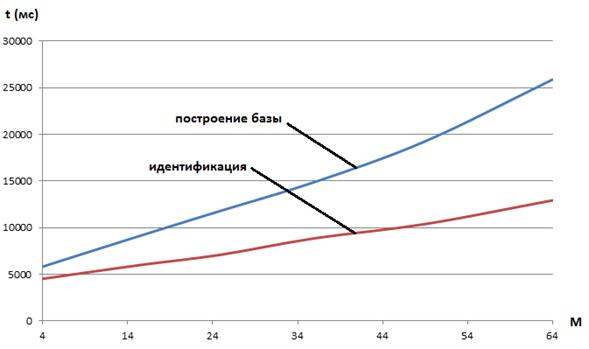
Рисунок 6 ‑ Время идентификации tв функции ХПГ: голос alex
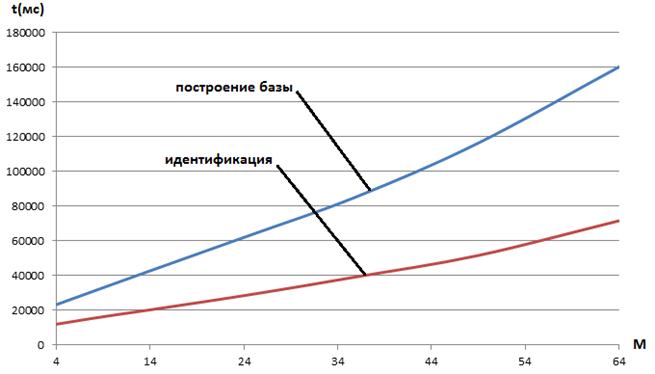
Рисунок 7 ‑ Время идентификации tв функции числа ХПГ: голос zarvox
Рисунки 6, 7 показывают, что в широких пределах изменения числа ХПГ для обоих рассматриваемых голосов имеет место почти линейная зависимость времени идентификации tв функции этого числа. Данный результат свидетельствует о высокой эффективности принятых алгоритмических и программных решений.
Минимальную ошибку обучения карты Кохонена min(Err) в функции числа ХПГ для рассматриваемых голосов иллюстрируют рисунки 8, 9.
Выбор оптимального значения числа Mопределяют две противоположные тенденции. С одной стороны, на основании малого числа ХПГ невозможно с высокой надежностью идентифицировать голос. С другой стороны, большое число этих признаков увеличивает вычислительные затраты на идентификацию и, тем самым, понижает ее скорость (если не говорить об использовании параллельных вычислений). На основании результатов данного исследования в качестве оптимального числа ХПГ выбрано ![]() . Если в процессе идентификации в базе данных системы VOICE обнаруживается два или более близких голосов, то может оказаться целесообразным увеличение этого числа.
. Если в процессе идентификации в базе данных системы VOICE обнаруживается два или более близких голосов, то может оказаться целесообразным увеличение этого числа.
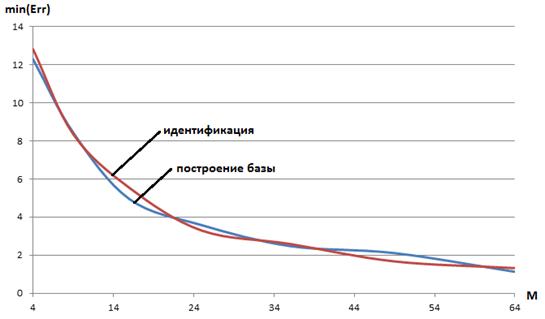
Рисунок 8 ‑ Минимальная ошибка обучения карты Кохонена min(Err) в функции числа ХПГ: голос alex
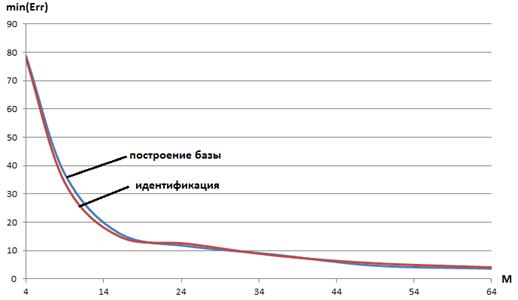
Рисунок 9 ‑ Минимальная ошибка обучения карты Кохонена min(Err) в функции числа ХПГ: голос zarvox
3.3. Исследование надежности идентификации. Выполнено также исследование надежности идентификации голоса в зависимости от величины отношения 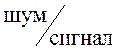 . В рассматриваемом диапазоне частот шум полагаем белым с нулевым математическим ожиданием. В качестве меры надежности классификации используем относительное число ошибочных решений.
. В рассматриваемом диапазоне частот шум полагаем белым с нулевым математическим ожиданием. В качестве меры надежности классификации используем относительное число ошибочных решений.
Результаты исследования представлены на рисунке 10. Рисунок показывает 100 % нулевое число ошибок распознавания голоса при отношении в диапазоне от нуля до 50 %. При увеличении указанного отношения от 50 до 100 % число ошибок повышается с 0 до ~ 40%
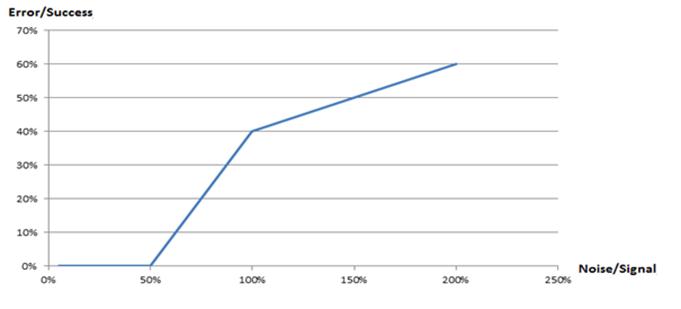
Рисунок 10 – Относительный уровень ошибок идентификации в функции уровня шума
В работе предложен метод идентификации личности по голосу. Выполнена программная реализация идентификатора, его тестирование и исследование эффективности. Результаты исследования показывают высокую эффективность принятых алгоритмических и программных решений, а также перспективность развития метода идентификации и его программной реализации.
Разработанная программная система VOICE может быть использована не только для идентификации человека по голосу, но и для распознавания голосов животных, например, птиц. Представляется перспективным использование системы для распознавания «голосов» различных технических объектов, например, с целью диагностики их состояния. Идентификатор может быть использован в телефонных конференциях для сокращения объема передаваемой информации и борьбы с шумом, обусловленным разговорами участников конференции.
Список литературы
1. Центр речевых технологий. Режим доступа: http://www.speechpro.ru/ (дата обращения 25.11.2012).
2. Матвеев Ю.Н. Технологии биометрической идентификации личности по голосу и другим модальностям // Вестник МГТУ им. Н.Э. Баумана. Электронное научно-техническое издание. 2012. № 3(3). Режим доступа: http://vestnik.bmstu.ru/catalog/it/biometric/91.html (дата обращения 25.11.2012).
3. Матвеев Ю.Н., Симончик К.К. Система идентификации дикторов по голосу для конкурса NIST SRE 2010 // ГрафиКон’2010: труды 20-й международной конференции по компьютерной графике и зрению. СПб.: СПбГУ ИТМО, 2010. С. 315-319.
4. Коваль С.Л. Комплексная методика идентификации дикторов по голосу и речи // Информатизация и информационная безопасность правоохранительных органов (Москва, 24 - 25 мая 2011 г.) : труды ХХ международной научной конференции. М.: Академия управления МВД России, 2011. С. 364-370.
5. Саймон Хайкин. Нейронные сети. Полный курс : пер. с англ. 2-е изд., испр. М.: Вильямс, 2008. 1103 с.
6. Трофимов А.Г., Скругин В.И. Адаптивный классификатор многомерных нестационарных сигналов на основе анализа динамических паттернов // Наука и образование. МГТУ им. Н.Э. Баумана. Электрон. журн. 2010. № 8. Режим доступа: http://technomag.edu.ru/doc/151934.html (дата обращения 25.11.2012).
7. Балакришнан А.В. Теория фильтрации Калмана : пер. с англ. М.: Мир, 1988. 168 с.
8. Акулов Л.Г., Муха Ю.П. Методы обработки электроэнцефалографических данных // Известия ВолгГТУ. Сер. Электроника, измерительная техника, радиотехника и связь. 2008. Т. 4, № 2. C. 66-69.
9. Грешилов А.А., Стакун В.А., Стакун А.А. Математические методы построения прогнозов. М.: Радиоисвязь, 1997. 112 с.
Публикации с ключевыми словами: идентификация личности по голосу, самоорганизующаяся карта Кохонена
Публикации со словами: идентификация личности по голосу, самоорганизующаяся карта Кохонена
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||