научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
#11 ноябрь 2005
И
И. П. Норенков, д-р техн. наук,
О. Т. Косачевский, МГТУ им. Н. Э. Баумана
Генетические алгоритмы комбинирования эвристик в задачах дискретной оптимизации
Статья посвящена алгоритмическим аспектам метода комбинирования эвристик для решения задач структурного синтеза и дискретной оптимизации. Предлагаются алгоритмы управления эвристиками, макромутациями в процессе локально-генетического поиска, отфильтровывания неперспективных экземпляров популяций. Приведены результаты численных экспериментов по оценке эффективности предлагаемых алгоритмов.
Введение. Генетические методы (ГМ) представляют собой мощное средство решения трудных задач дискретной оптимизации и сводящихся к ним задач структурного синтеза во многих приложениях. Известны примеры применения ГМ к решению задач на графах [1], систем логических уравнений [2], для синтеза расписаний [3—7], компоновки и размещения элементов в радиоэлектронной аппаратуре [8], конструирования механизмов [9] и т. п.
К числу генетических методов относится метод комбинирования эвристик (НСМ — HeuristicsCombinationMethod), основные положения и преимущества которого обсуждены в [10]. Высокая эффективность метода во многом обусловлена особенностями используемых в нем алгоритмов. Основными среди алгоритмических факторов, влияющих на эффективность, следует назвать используемый набор эвристик, вероятности их выбора в операторах мутации и формирования начального поколения, глубину локального поиска, размер макромутаций, характер расположения в хромосоме мутируемых генов.
Данная статья посвящена обсуждению факторов, определяющих эффективность решения задач методом НСМ, и описанию оригинальных алгоритмов НСМ, она может рассматриваться как продолжение работы [10], в которой были представлены постановки следующих задач для решения методом НСМ:
· ADP (ApplicationDistributionProblem) — задача распределения приложений по подсетям вычислительной сети (разновидность задачи компоновки) с минимизацией внешнего трафика;
· CLS — задача кластеризации — разделение множества компонентов на подмножества (кластеры) одинаковой мощности с минимизацией связей между кластерами;
· 2DBPP (2DBinPackingProblem) — задача разногабаритных компонентов (или упаковки грузов в контейнер);
· VRPTW (VehicleRoutingProblemwithTimeWindows) — задача маршрутизации транспортных средств с временными окнами;
· OSSP (OpenShopSchedulingProblem) — многостадийная задача синтеза расписаний (задача Гиффлера-Томпсона).
Любая из этих задач может быть декомпозирована на ряд однотипных локальных подзадач. В НСМ для каждой подзадачи формируется набор правил, из которых, в свою очередь, формируются эвристики.
Тестовыми задачами, на которые будут ссылки в дальнейшем, являются:
· ADP_39 (тест для ADP) — число приложений n = 39, максимальное число подсетей m = 10;
· CLS_80 (тест для CLS) — число размещаемых элементов m = 80, число кластеров m= 4;
· ВРР100 (тест для 2DBPP) — число компонентов n = 100;
· VRP_80 (тест для VRPTW) — число узлов сети w = 80, число узлов-потребителей продукта n = 25, число узлов-источников продукта k = 40, число серверов (транспортных средств) m = 12;
· N105 (тест для OSSP) — число работ n = 105, число стадий p = 4, число серверов m= 15;
· N25 — то же, что и N105, но n = 25.
В начале данной статьи для лучшего понимания последующего материала приведены краткие сведения о простом генетическом алгоритме (ГА) и об используемом гибридном эволюционно-генетическом алгоритме (ЭГА). В следующей секции статьи изложены способы управления эвристиками, частично уже представленные в [7]. В частности, в [7] показаны преимущества ЭГА перед чисто генетическими однопопуляционным и много-популяционным алгоритмами в задачах синтеза расписаний. В последующих секциях статьи представлены алгоритмы управления макромутациями и фильтрации хромосом. В заключительной части обсуждаются полученные результаты.
Простой и гибридный генетические алгоритмы. В простом ГА исходное поколение размером Np хромосом формируется случайным выбором значений каждого гена в каждой хромосоме.
Далее начинается цикл эволюции. На каждом витке этого цикла формируется Np хромосом нового поколения с помощью операторов выбора родителей, кроссовера, мутации и селекции. Вероятность выбора хромосомы X в качестве родителя тем выше, чем лучше значение соответствующей ей функции полезности (целевой функции) F.
Мутация заключается в замене значений некоторых генов в родительской хромосоме на случайные значения. Для выбора позиций мутируемых генов и частоты мутаций используются те или иные правила, например, каждый очередной ген мутирует с заданной вероятностью р.
Кроссовер выполняется по отношению пары родителей и включает разрыв хромосом в одной или нескольких позициях и рекомбинацию образовавшихся фрагментов (рис. 1). В результате получается пара хромосом потомков.

Рис. 1. Иллюстрация кроссовера
Из наиболее перспективных мутированных хромосом и хромосом потомков и селектируются Np хромосом нового поколения.
Эволюционно-генетический алгоритм сочетает в себе генетические операторы и операторы локального спуска (simplehillclimbing) [11, 12] и потому его часто называют локально-генетическим. Локальный спуск осуществляется в отношении перспективных дочерних хромосом, имеющих после кроссовера и рекомбинации значение функции полезности F0, и заключается в выполнении не менее K попыток улучшения F0 с помощью макромутаций. Макромутация в НСМ — это присвоение избранным генам случайных значений из диапазона номеров эвристик, вероятность задания i-й эвристики есть qi. Если попытка оказывается успешной, то вновь гарантируется выполнение не менее K попыток. Другими словами, локальный спуск заканчивается после K случившихся подряд неудачных попыток. Параметр K будем называть глубиной макромутаций или глубиной локального поиска, а число одновременно мутируемых генов R — размером макромутаций.
Управление эвристиками. Управление эвристиками включает, во-первых, формирование рабочего набора эвристик из числа возможных сочетаний правил для разных частей подзадач, во-вторых, выбор вероятностей qt использования эвристик в процессе решения задачи.
Кандидатами на включение в рабочий набор при наличии Участей в каждой подзадаче и r правил для каждой из них являются г разных эвристик. Однако на практике используют только небольшое число возможных эвристик. Так, в решаемых нами задачах VRPTW в трех частях, соответствующих выбору потребителя, источника и сервера, использовались соответственно 3, 2 и 3 правила, т. е. общее число возможных эвристик равно 18. В задаче ADV в первой части (выбор приложения) фигурируют три правила, а во второй части (выбор подсети) — четыре правила, т. е. всего может быть 12 эвристик. Однако в рабочие наборы в этих задачах было включено по 5 эвристик. В многостадийных задачах синтеза расписаний нами использовалось 8 эвристик. Уменьшение числа эвристик снижает размерность поискового подпространства, но при этом должно обеспечиваться необходимое разнообразие эвристик для сохранения в поисковом подпространстве оптимальных решений и их окрестностей.
Первоначальное включение эвристик в рабочий набор выполняется по субъективным предпочтениям. Обычно субъективизм не вызывает отрицательных последствий, так как первоначальный набор можно сделать избыточным с использованием всех правил и скорректировать его после пробных прогонов. Эти пробные прогоны предназначены для определения qi, и если qi окажется близким к нулю, то i-я эвристика станет кандидатом на исключение из рабочего набора.
Определение вероятностей qt использования эвристик в процедурах мутации и генерации начального поколения является важнейшим фактором управления эвристиками. Были предложены три алгоритма определения qi.
А1. Алгоритм выбора вероятности qi использования i-й эвристики по результатам применения каждой эвристики в отдельности. Вероятность qi выбирается тем большей, чем лучше результат применения i-й эвристики:
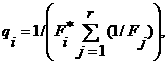
где Fi — значение целевой функции при использовании единственной i-й эвристики; r — число эвристик. Как показали результаты численных экспериментов, в случае синтеза расписаний этот алгоритм можно использовать в задачах с нежесткими ограничениями, причем при выборе qi штрафы за нарушение ограничений в Fi учитываться не должны.
Таблица1
Эвристика | F/Z (ADP_39) | F (CLS_80) | F/Z (VRP_80) | F/Z (N25) |
Э1 | 1857/1857 | 5601 | 705/505 | 8848/5678 |
Э2 | 1870/1870 | 2024 | 1638/648 | 6970/5806 |
ЭЗ | 4040/0 | 3263 | 1407/1307 | 9179/5970 |
Э4 | 4040/0 | 2008 | 1516/1416 | 10259/6099 |
Э5 | 4040/0 | 2864 | 816/796 | 6091/5951 |
Э6 | — | — | — | 6006/5866 |
Э7 | — | — | — | 8076/5946 |
Э8 | — | — | — | 12381/5191 |
А2. Алгоритм пробного прогона задачи, при котором
qi = vi/g (1)
где vi — число генов с номером i-й эвристики в лучшей хромосоме после пробного просчета, соответствующего одному—двум поколениям; g — общее число генов в хромосоме. Другими словами, qi есть частость появления номера i-й эвристики в лучшей из имеющихся хромосом.
A3. Самонастраивающийся алгоритм, при котором qiдля k-го поколения определяется по формуле (1), в которой vi подсчитано по лучшей хромосоме (k- 1)-го поколения.
В рамках алгоритма А1 были проведены расчеты функций полезности, соответствующие использованию каждой эвристики в отдельности. Результаты приведены в табл. 1, где Fи Z— значения функции полезности при использовании соответствующей эвристики с учетом и без учета штрафов соответственно.
В табл. 2 приведены результаты нескольких решений задачи ADP_39 гибридным методом НСМ с использованием различных алгоритмов определения qi. Там же для сравнения даны результаты применения простого генетического алгоритма НСМ (без применения процедур локального поиска) с равновероятным выбором эвристик. Решение в каждом варианте (прогоне) задачи по гибридному методу НСМ продолжалось на протяжении 25 поколений, что соответствует приблизительно Ev = 3500 обращений к процедуре вычисления целевой функции (обращений к модели приложения). Другие условия эксперимента: глубина макромутаций K= 6, размер популяции Np = 15. Решение по простому ГА выполнялось при большем Np так, чтобы было Ev = 3500.
Таблица 2.
Метод | Значения целевой функции Fв отдельных вариантах решения | Среднее значение F |
Простой генетический алгоритм | 1378; 1395; 1488; 1518; 1575 | 1471 |
Гибридный НСМ с равными значениями qiдля всех эвристик | 926; 1012; 1056; 1068; 1108 | 1034 |
Гибридный НСМ с алго- ритмом А2 | 913; 913; 919; 919; 929 | 919 |
То же с алгоритмом A3 | 913; 928; 981; 988; 1039 | 970 |
Результаты численных расчетов убедительно свидетельствуют в пользу гибридного алгоритма, причем с рационально выбранными значениями qi, а среди алгоритмов выбора qi лучше себя зарекомендовал алгоритм А2.
В табл. 3 приведены результаты нескольких вариантов решения задачи VRP_80, полученные к 30-му поколению, Ev приблизительно 5400, K= 10, Np = 15 (простой генетический алгоритм выполнялся при Np = 100, Ev = 50). В этой задаче наилучшие результаты зафиксированы при использовании самонастраивающегося алгоритма A3. Отметим, что затраты машинного времени на решение задачи невелики: на ЭВМ IBMPentium 100 МГц — 1,7 с на 100 оценок целевой функции, т. е. не более двух минут на полное решение задачи.
Таблица 3
Метод | Значения целевой функции F в отдельных вариантах решения | Среднее значение F |
Простой генетический алгоритм | 543; 578; 593; 598; 663 | 595 |
Гибридный НСМ с равными значениями qiдля всех эвристик | 516; 529; 545; 548; 577 | 543 |
Гибридный НСМ с алгоритмом А2 | 496; 503; 510; 522; 542 | 515 |
То же с алгоритмом A3 | 494; 495; 503; 504; 504 | 500 |
То же с алгоритмом А1 | 495; 495; 496; 506; 569 | 512 |
В этих экспериментах подтверждены выводы, сделанные по результатам решения задач ADP_39, за исключением того, что самонастраивающийся алгоритм оказался несколько лучше других алгоритмов выбора qi.
Данные таблиц 1—3 интересны также тем, что они убедительно свидетельствуют о преимуществе НСМ перед обычными эвристическими методами решения задач дискретной оптимизации. Так, в задаче VRP_80 лучший из эвристических методов дал значение целевой функции F= 705, в то время как метод НСМ с алгоритмом A3 обеспечивает получение значений Fв диапазоне 494...504. В задаче ADP_39 лучшему из эвристических методов соответствует F= 1857, а НСМ с алгоритмом А2 показывает результаты в диапазоне 913...929. В задаче CLS_80 лучший эвристический метод дает значение целевой функции F = 2008, в то время как во всех выполненных вариантах решения по НСМ получено оптимальное значение F= 1905 при средних затратах Ev = 725.
Управление макромутациями. Управление макромутациями подразумевает принятие решений по следующим вопросам:
· позиционирование — расположение мутируемых генов в хромосоме;
· размер макромутаций R — число мутируемых генов на одном шаге локального поиска;
· глубина макромутаций K — максимально допустимое число идущих подряд безуспешных попыток улучшить результат локального поиска.
В большинстве задач возможны два основных способа позиционирования: EGA1 — распределенный случайный и EGA2 — сосредоточенный регулярный. В EGA1 позиция каждого мутируемого гена выбирается случайно с равной вероятностью p = 1/g, g — число генов в хромосоме. В EGA2 множество мутируемых генов составляют гены, расположенные в соседних локусах, случайным образом выбирается лишь позиция первого гена последовательности среди g-R первых генов.
В некоторых задачах, имеющих то или иное секционирование, возможны дополнительные схемы позиционирования. Примерами таких задач могут служить многостадийные задачи синтеза расписаний. Для них нами использовался также алгоритм EGA3, реализующий распределенный регулярный способ позиционирования [7].
В [7] приведены данные о том, что в задачах синтеза расписаний алгоритм EGA2 более эффективен в сравнении с EGA1. Предпочтительность EGA2 перед EGA1 проявилась, хотя и незначительно, также в задаче ВРР_100 (в отличие от задач ADP и VRPTW, где явного предпочтения одного из этих алгоритмов перед другим не замечено).
Сравнение по эффективности EGA1 и EGA2 на ВРР_100 проводилось в условиях Np = 21, K= 40, выбор qi по алгоритму А2 с соотношением q1: q2: q3: q4 = 3: 2: 2: 3. Было выполнено несколько прогонов задачи на протяжении восьми поколений каждый (один прогон занимал около 3 мин времени на IBMPentium-100). К девятому поколению в большинстве случаев наблюдались признаки стагнации. Среднее, по прогонам достигнутое значение целевой функции F в алгоритме EGA1 составило 511, а в алгоритме EGA2 — 479, что свидетельствует в пользу EGA2. Однако даже в EGA2 разброс значений Fот прогона к прогону оказался значительным — от 430 до 555, что говорит о сохранении опасности ранней стагнации.
Поэтому для решения задач, подобных ВРР_100, потребовалась разработка группы дополнительных алгоритмов ММС (MacromutationControl). Это алгоритмы управления размером макромутаций R. Применявшиеся до этого алгоритмы имели R = const и в задачах 2DBPP умеренного размера так же, как и в задачах VRP_80 и ADP_39, с их помощью удавалось получать удовлетворительные решения при постоянных значениях R, выбираемых в диапазоне 3—12. Однако в задаче ВРР_100 они из-за отмеченного разброса значений F могли привести к неудовлетворительным результатам размещения.
Алгоритмы ММС повышают эффективность поиска благодаря переменной величине R и процедуре Re-старта.
В алгоритме ММС1 R — случайная величина, равномерная распределенная в диапазоне [Rmin, Rmax], причем экспериментально установлено, что для задач 2DBPPRmax должно быть заметно больше, чем ранее использовавшиеся значения 3...12. В экспериментах принималось Rmin = 3, Rmax = 36.
В алгоритме ММС2 переменными являются не только R, но и величины Rmin и Rmax, причем в первых поколениях R должно тяготеть к большим значениям с сужением диапазона и его перемещением в область меньших R по мере развития популяции. Собственно идея алгоритма ММС2 основана на предположении, что стагнация при плохих значениях F обусловлена "застреванием" поиска в локальных экстремумах (понятие локального экстремума связано с метризацией дискретного пространства, в котором расстояние между хромосомами А и В есть число генов в А и В с неодинаковыми значениями; из этого следуют понятия окрестности хромосомы и локального экстремума). Чем больше область D притяжения локального экстремума и чем глубже в этой локальной области находится текущая точка поиска, тем труднее выйти из D. Малые значения R недостаточны для выхода из D, в то же время они "загоняют" текущую точку глубже в локальную яму, уменьшая возможности выхода из нее. Следовательно, упоминавшаяся стагнация наступит, если в начале поиска текущая точка оказалась в зоне плохого локального экстремума.
Улучшить ситуацию можно, если расширить возможности выхода из D, причем это нужно сделать до углубления текущей точки в локальную яму. Этим и обосновывается ММС2, так как выход из D более вероятен при больших R, а углубление — при малых R. Конечно, перемещение между зонами притяжения разных экстремумов необязательно приводит в зону лучшего локального экстремума. Но поскольку это перемещение сопровождается улучшением значений F и если справедлива гипотеза положительной корреляции текущего значения F и соответствующего локально экстремального значения F, то ММС2 способствует преодолению ранней стагнации.
Более радикальный способ преодоления ранней стагнации — существенное обновление состава популяции с помощью принудительных макромутаций, названных в [13] Re-стартом. В предыдущих алгоритмах любая макромутация, не приводящая к улучшению Fдля мутируемой хромосомы, отвергалась и не отражалась в новом поколении. Принудительная макромутация отличается тем, что ее результаты принимаются в любом случае. Этот подход реализован в алгоритмах ММСЗ и ММС4, аналогичных алгоритмам ММС1 и ММС2, но в них в одном из промежуточных поколений выбранная для локального улучшения дочерняя хромосома подвергается сначала принудительной макромутации, после чего следует обычный цикл локального улучшения.
В выполненных экспериментах на задаче ВРР_100 в ММС1 для R был принят диапазон [3, 36]. В ММС2 динамика изменения диапазона по поколениям представлена в табл. 4. В ММСЗ и ММС4 в шестом поколении выполнялась принудительная макромутация, в поколениях 7—11 использовались те же значения Rmin, Rmax, что и в поколениях 1—5.
Таблица 4.
Номера поколений | 1 | 2 | 3 | 4 и далее |
[Rmin, Rmax] | [20 ,36] | [11 ,30] | [6, 20] | [3, 16] |
На рис. 2 показаны усредненные по трем прогонам значения целевой функции F, полученные в процессе оптимизации по алгоритмам ММСЗ и ММС4, здесь L — номер поколения. Разброс значений FbMMC4 в пяти прогонах после 11-го поколения был в пределах [431; 489].
Справедливость приведенного обоснования ММС можно проверить только экспериментально на большом числе опытов. Доступный нам объем экспериментального материала не позволяет делать окончательные заключения, но данные экспериментов свидетельствуют о предпочтительности применения Re-старта и переменных диапазонов для размеров макромутаций R в задачах 2DBPP.

Рис. 2. Зависимость среднего значения целевой функции от номера поколения
Следует заметить, что в задачах ADP и VRPTW не замечено повышения эффективности при применении ММС.
Что касается влияния глубины локального поиска K на эффективность решения, то можно отметить не ярко выраженное повышение эффективности с ростом K в диапазоне 0,1...0,8 от числа генов g (но при этом естественно растут и затраты времени на решение).
Фильтрация. Фильтрация — один из способов повышения эффективности генетического поиска, в частности, преодоления ранней стагнации. Известен ряд схем фильтрации.
Идея фильтрации используется достаточно широко. Например, такой необходимый в ГМ оператор, как селекция, фактически реализует фильтрацию — отбрасывание неудачных хромосом, генерируемых в операторах кроссовера или мутации. Одним из примеров фильтрации может служить упомянутый макрооператор Re-старт. Re-старт предназначен для преодоления ранней стагнации и заключается в переходе от текущего поколения к новому поколению полной или частичной заменой значений генов во всех хромосомах.
В разрабатываемых для НСМ эволюционно-генетических алгоритмах можно использовать несколько стадий фильтрации (фильтров), причем одним из требований является экономичность — малые затраты времени на возникающие дополнительные вычисления.
Сначала формируется исходное поколение. При этом фильтр Ф1 осуществляет среди генерируемых случайным образом хромосом отбор тех, у которых целевая функция лучше некоторого порогового значения TS1, т. е. F < TS1. Отобранные в Ф1 хромосомы подвергаются процедуре Р1 локального улучшения с некоторой глубиной локального поиска Кнп и поступают на фильтр Ф2, в котором отбираются члены исходного поколения по условию F < TS2.
В процессе генетического поиска могут использоваться фильтры ФЗ и Ф4, аналогичные по своему назначению фильтрам Ф1 и Ф2. В ФЗ проходят отбор дочерние хромосомы, получаемые в результате кроссовера, по условию F< TS3. В Ф4 фильтруются хромосомы, которые после ФЗ прошли также через процедуру Р2 локального спуска.
В использовавшихся нами алгоритмах преимущественно применялись фильтры Ф1, Ф2 и ФЗ. В Ф1 фигурировал постоянный порог TS1 = const. То же относится к Ф2, где TS2 < TS1. В ФЗ использовался плавающий порог:
TS3 = G + delta;
if(F< TS3)
(success; b = delta - al*Fmin; if (b >= 0) delta = b;}
else (the individual is discarded;
delta = delta + a2*Fmin;}
Здесь G, al и a2 — постоянные коэффициенты, Frnin — лучшее из значений целевой функции, достигнутое к данному моменту поиска.
Возможно использование и других способов фильтрации, например, отбор лучших экземпляров среди множества полученных кандидатов.
Таблица 5
№ | Вариант задачи | F(N25) | Fср(N25) | F(N105) | Fср(N105) |
1 | Обычный эвристический метод — использование единственной эвристики (лучшей из восьми) | 6006 | — | 23084 | — |
2 | Случайный выбор (метод Монте-Карло) со всеми восемью эвристиками | 5585 | — | — | — |
3 | Простой генетический алгоритм со всеми восемью эвристи-ками без фильтрации: Np = 70 | 5524, 5538, 5547 | 5536 | — | 22607 |
4 | Как № 3, но с использованием отобранного подмножества из четырех эвристик (q1:q2:q6:q8 = 2:1:1:4) | 5356, 5366, 5390 | 5371 | — | 22424 |
5 | Случайный выбор по методу Монте-Карло с подмножеством из четырех эвристик | 5387, 5409, 5430 | 5409 | — | — |
6 | Локальный поиск (hillclimbing) без кроссовера | 5401, 5425, 5431 | 5419 | — | — |
7 | Как № 4, но с использованием фильтра Ф1 и локального спуска Р1 | 5355, 5389, 5412 | 5385 | — | 22352 |
8 | Как № 4, но с использованием Ф1, Р1 и Ф2 | 5358, 5359, 5397 | 5371 | — | 22283 |
9 | Как № 4, но с использованием также ФЗ | 5315, 5345, 5381 | 5347 | — | — |
10 | EGA2 (используются Ф1, Ф2, ФЗ, PI, P2 и алгоритм выбора эвристик А1) | 5296, 5297, 5310 | 5301 | — | — |
11 | Как № 10, но EGA3 | 5300, 5305, 5321 | 5309 | — | — |
12 | Как № 10, но с комбинацией алгоритмов EGA2 и EGA3 (отношение вероятностей их применения 7:3) | 5276, 5279, 5284, 5286, 5288, 5294 | 5285 | 21852;21923;21933; 21936;21953;21960; 21968 | 21932 |
В табл. 5 представлены результаты экспериментов, полученные после приблизительно 32,5 тыс. обращений к процедуре вычисления целевой функции F в каждом прогоне на задаче синтеза расписаний N25 и после 30...36 тысяч на задаче N105.
Данные табл. 5 свидетельствуют:
1) эволюционно-генетические алгоритмы превосходят по эффективности простые случайный (Монте-Карло) и генетический алгоритмы;
2) как генетический, так и локальный поиск в НСМ по отдельности недостаточно эффективны;
3) фильтрация способствует повышению эффективности решения задач.
Интересно отметить, что в N25 эффективность мало зависит от параметров Np, варьируемого в пределах 13...70, и K в пределах 20...90. Слабая зависимость эффективности от Np в НСМ обусловлена наличием локального поиска.
* * *
Таким образом, в эволюционно-генетических алгоритмах метода НСМ имеется ряд альтернативных процедур и параметров, управляя которыми можно добиваться повышения эффективности решения задач. В статье рассмотрены такие факторы, как состав эвристик, вероятности их выбора в операторах макромутации, расположение мутируемых генов, глубина и размер макромутаций, применение Re-старта, фильтрация хромосом. Проиллюстрированы возможности решения с помощью НСМ широкого класса задач дискретной оптимизации.
Список литературы
1. Esbensen H. Finding (Near-)Optimal Steiner Trees in Large Graphs // Proc. of 6th Int. Conf. on GA, Morgan Kaufmann Publ., San Francisco, 1995.
2. Norenkov I. P., Kosahevsky О. Т. Genetic Method for Satisfiability Problem Solving// Proc. of EWITD'96. Moscow: ICST1, 1996.
3. Whitley D., Starkweather Т., Fuduay D. Scheduling Problems and Traveling Saleman: the Genetic Edge Recombination Operator // Proc. of 3d Int. Conf. on GA, 1989.
4. Nakano R. Conventional Genetic Algorithm for Job Shop Problems // Proc. of 4th Int. Conf. on GA, Morgan Kaufmann Publ., San Francisco, 1991.
5. Brims R. Direct Chromosome Representation and Advanced Genetic Operators for Production Scheduling // Proc. of 5th Int. Conf. on GA, 1993.
6. Kobayashi S., Ono I., Yamamura M. An Efficient Genetic Algorithm for Job Shop Scheduling Problem // Proc. of 6th Int. Conf. onGA, MorganKaufmannPubl., SanFrancisco, 1995.
7. Норенков И. П. Генетические методы структурного синтеза проектных решений // Информационные технологии, 1998, № 1. С. 9-13.
8. Батищев Д. И., Морозов В. Ф., Власов С. Е., Булгаков И. В. Топологический синтез аналого-цифровых микроэлектронных устройств // Информационные технологии, 1996, № 2. С. 39-43.
9. Kalyanmoy D., Saxcna V. Car Suspension Design for Comfort Using Genetic Algorithms // Proc. of 7th Conf. on GA, 1997.
10. Норенков И. П. Эвристики и их комбинации в генетических методах дискретной оптимизации. Информационные технологии, 1999, № 1.
11. Norenkov I. P., Goodman E. D. Solving Scheduling Problems via Evolutionary Methods for Rule Sequence Optimization., Soft Computing in Engineering Design and Manufacture, P. K. Chawdry, R. Roy, R. K. Pant, eds., Springer Verlag, 1998.
12. Ishibuchi H., Murata D., Tomioka S. Effectiveness of Genetic Local Search Algorithms // Proc. of 7th Conf. on GA, 1997.
13.Maresky J., Davidor Y., Gitler D., Aharoni G., Barak A. Selectively Destructive Re-start // Proc. of 6th Conf. on GA, 1995.
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ, № 2, 1999
МЕТОДЫ ОПТИМИЗАЦИИ
Ключевые слова: Генетические алгоритмы, комбинирование эвристик, дискретная оптимизация, эффективные алгоритмы, кроссовер, макромутации, фильтрация.
Публикации с ключевыми словами: фильтрация, дискретная оптимизация, комбинирование эвристик, эффективные алгоритмы, кроссовер, макромутации, генетические алгоритмы
Публикации со словами: фильтрация, дискретная оптимизация, комбинирование эвристик, эффективные алгоритмы, кроссовер, макромутации, генетические алгоритмы
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||