научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
#9 сентябрь 2007
И.П. Норенков,
Н.М. Арутюнян
МГТУ им. Н.Э. Баумана
1. Состояние проблемы структурного синтеза в проектировании и логистике
1.1. Примеры задач структурного синтеза проектных решений
Проектирование – итерационный процесс, в котором чередуются процедуры синтеза и анализа. Синтез – это создание проектного решения в виде описания облика изделия, его конструкции, структурной, функциональной или принципиальной схемы. Анализ – это оценка результатов синтеза. В современных САПР преимущественно развиты математическое и программное обеспечения процедур анализа. Синтез – трудно формализуемая процедура. Формализация достигнута лишь при решении некоторых задач в отдельных приложениях. Примеры формализуемых процедур и, следовательно, решаемых в САПР задач в автоматическом режиме – размещение электронных компонентов на печатных платах или кристаллах БИС, синтез маршрутов технологических процессов в машиностроении, раскрой материалов и некоторые другие. В большинстве случаев синтез выполняется человеком в интерактивном режиме работы с ЭВМ.
Известны недостатки неавтоматизированного синтеза:
а) решения зачастую оказываются далекими от оптимальных;
б) по мере усложнения проектируемых изделий возможности человека в решении задач синтеза сужаются;
в) растут затраты времени на проектирование.
Полное исключение человека из процесса принятия решений при проектировании нецелесообразно и зачастую невозможно. Однако дальнейшее развитие математического обеспечения САПР должно быть направлено, в первую очередь, на снижение указанных недостатков, т.е. на поиск новых более эффективных методов структурного синтеза проектных решений.
При разработке новых средств автоматизированного проектирования необходимо располагать, во-первых, критериями оценки эффективности предлагаемых методов, во-вторых, тестовыми задачами, отражающими особенности широких классов проектных задач.
К основным критериям эффективности моделей, методов и алгоритмов автоматизированного проектирования относятся:
а) точность решения задач;
б) затраты вычислительных ресурсов на решение задач, причем основной дефицит при решении задач обычно представляют затраты машинного времени.
Тестовые задачи должны отражать характерные особенности классов задач структурного синтеза проектных решений. Поэтому необходимо выделить классы задач, которые охватывают достаточно широкий круг практически важных задач структурного синтеза.
Проектные решения могут быть связаны с определением форм и расположением компонентов проектируемого изделия в пространстве или их расположением как в пространстве, так и во времени. Соответственно будем различать классы задач принятия пространственных и пространственно-временных решений.
Типичные задачи пространственного синтеза:
Ø компоновка оборудования [1,2];
Ø размещение компонентов [2,3];
Ø синтез топологии сети соединений [2,4];
Ø раскрой и упаковка [5];
Ø потоковые задачи [6];
Ø геометрический синтез форм деталей [7];
Ø синтез многоэлементных механических конструкций [8] и др.
Компоновка заключается в распределении n заданных элементов (конструктивов) в m блоках. Элементами могут быть микросхемы, распределяемые между типовыми элементами замены; приборы, размещаемые в отсеках корабля; работы, назначаемые на выполнение конкретным исполнителям, и др. Типичными ограничениями при компоновке являются ограничение на вместимость блоков, число межблочных связей, несовместимость элементов отдельных типов друг с другом и потому необходимость их распределения в разные блоки и др.
Например, при проектировании электронных устройств основной задачей компоновки является разрезание большой схемы (структурной, функциональной, логической, принципиальной) на части (микросборки, ТЭЗы, узлы и т. п.), Разрезание выполняется с минимизацией числа связей между частями.
К типу задач компоновки относится также ряд других задач. По своей постановке к ним близка актуальная задача распределения частот между сотами в системах мобильной связи [9,10]. Здесь компонентами являются соты, а блоками – диапазоны частот. Задано расположение сот и требуется обеспечить максимальное удаление сот с одинаковыми частотными диапазонами друг от друга. Другим примером этого типа задач является известная задача о назначениях.
После компоновки обычно решается задачи размещения компонентов в блоках. Результаты размещения определяют степени удаленности компонентов друг от друга и, следовательно, влияют на время передачи продукции или информации между компонентами. Например, в микроэлектронике от результатов размещения существенно зависят возможности трассировки и, следовательно, быстродействие СБИС, так как основные задержки сигналов приходятся именно на соединения.
В САПР находят применение следующие критерии размещения:
- суммарная длина всех соединений;
- расстояние между элементами, соединенными наибольшим числом связей;
- длина наиболее длинных связей;
- число межслойных переходов;
- параметры паразитных связей между элементами и проводниками и др.
Различают задачи с заданной схемой соединений и с заданным трафиком между компонентами сети.
Первый тип характерен для проектирования в радиоэлектронике [2], где после размещения или одновременно с размещением решается задача трассировки соединений. При этом заданное множество соединений надо проложить в коммутационном пространстве СБИС или печатной платы.
Второй тип задач топологического синтеза характерен для проектирования транспортных или информационных сетей [6]. В этих приложениях задается интенсивность потока некоторой субстанции между узлами сети и необходимо выбрать систему трасс для передачи субстанции, минимизируя затраты на создание или эксплуатацию транспортной системы при обеспечении трафика заданного объема.
В задачах раскроя задан некоторый материал в виде полос или стержней, из которых нужно выкроить требуемое число деталей определенных типов (размеров), причем оптимальным решением задачи будет то, при котором расходы материала минимизированы. Задачи различаются размерностью и формой получаемых деталей. Так, в задаче одномерного раскроя полосы и детали характеризуются только одним параметром – длиной. Исходными данными являются множества раскраиваемых полос и типов деталей, длины полос и деталей, число требуемых деталей каждого типа. Результатом решения задачи одномерного раскроя должна быть раскройная матрица, элементы которой равны числу деталей i-го типа, выкраиваемых в соответствии с j-м шаблоном, и вектор интенсивностей применения j-го шаблона.
Характерным примером задач упаковки является задача двумерной упаковки предметов прямоугольной формы в полубесконечную полосу (контейнер). В этой задаче заданы множество разногабаритных прямоугольных предметов высотой Di и шириной Li, предметы нужно упаковать в контейнер с открытым верхом и шириной W. Возможны варианты задачи с ориентацией прямоугольников как с основанием, параллельным дну контейнера, так и с их поворотом на 90°.
В качестве минимизируемой целевой функции задачи двумерной упаковки используют высоту занятой части контейнера, а ограничениями служат условия неперекрытия предметов и их расположения в пределах полосы шириной W.
Другими примерами задач этого типа могут служить задачи фигурного раскроя, гильотинного раскроя, трехмерной ортогональной упаковки.
Потоковые задачи характерны для проектирования транспортных и вычислительных сетей. В этих задачах требуется для заданной топологии сети определить пропускную способность дуг, соединяющих узлы сети, минимизируя затраты на реализацию дуг (линий связи). Различают задачи определения максимально возможного в данной сети потока и распределения общего потока по дугам сети. Усложняющим фактором для решения задач этого типа является необходимость учета возможных отказов линий передачи. При этом необходимо предусмотреть такие пропускные способности дуг, при которых возможно успешное перераспределение потока в случае отказов. Минимизируемой целевой функцией в этих задачах является общая стоимость создания или эксплуатации сети.
Геометрический синтез форм деталей - одна из наиболее распространенных задач, решаемых в САПР в интерактивном режиме. Для поддержки геометрического синтеза разработан аппарат машинной графики и геометрического моделирования, наиболее известные CAD программы (CATIA, Unigraphics, ProEngineer и др.) прежде всего ориентированы на синтез конструкций. Наличие мощного программного обеспечения геометрического моделирования позволяет успешно решать задачи геометрического синтеза в интерактивном режиме работы пользователя без привлечения средств автоматического синтеза конструкций.
Примером задач синтеза многоэлементных механических конструкций может служить задача синтеза ударопрочной конструкции передней части автомобиля [8], заключающаяся в определении, во-первых, числа и размеров сечений силовых балочных элементов, во-вторых, мест их расположении в кузове передней части. Требуется минимизировать скорость салона (представленного точкой, жестко связанной с передним щитком) в конечный момент расчетного времени при соблюдении ограничений на массу балочных элементов и на максимальное ускорение салона во время торможения.
Типичные задачи пространственно-временного синтеза:
Ø одно- и многостадийные задачи синтеза расписаний [11-13];
Ø маршрутизация транспортных средств [14].
В задачах синтеза расписаний задано множество n компонентов, называемых работами, и m блоков, называемых машинами или серверами, и требуется распределить работы по машинам и во времени, причем одна работа не может одновременно выполняться более чем на одной машине и одна машина не может одновременно обслуживать более одной работы. Каждая работа может проходить одну или несколько стадий обслуживания, на каждой стадии имеется свое множество машин. Требуется минимизировать стоимостные затраты на выполнение заданной совокупности работ при ограничениях на сроки выполнения. Часто в задачах приходится учитывать также затраты на наладку машин, расходы дополнительных ресурсов и т.п.
Примерами задач синтеза расписаний могут служить задачи расчета расписаний вычислительных процессов в сетях и вычислительных системах, разработка технологических процессов в CAM системах, планирование работ при управлении проектами и др.
Среди задач проектирования маршрутов транспортных средств при перевозке различных грузов одной из наиболее трудных для решения считается задача маршрутизации транспортных средств с временными окнами. Временным окном здесь называют временной интервал, в который нужно выполнить заказ на перевозку. В задаче заданы: сеть узлов (пунктов) и расстояния между пунктами; число и размещение в сети узлов, являющихся потребителями и источниками продукта; временные окна заказов; число, характеристики и начальное расположение в сети транспортных средств, предназначенных для перевозки продуктов. Требуется найти график движения транспортных средств для выполнения всех заказов с минимальными затратами средств и минимальными отклонениями от заданных сроков.
1.2. Подходы к решению задач структурного синтеза проектных решений
В разделе 1.1 преимущественно охарактеризованы задачи структурного синтеза, для которых достигнута формализация и существуют математические постановки в виде задач дискретной оптимизации. Следует однако отметить, что, как правило, задачи описанных классов оказываются NP-трудными и, следовательно, точное их решение возможно лишь при малом размере задач. К сожалению, практически важные задачи имеют размеры, существенно превышающие возможности точного решения.
Наряду с формализуемыми задачами имеются типы задач, для которых формализация не достигнута.
Поэтому все подходы к решению задач структурного синтеза в САПР подразделяются на две группы:
- использование интеллектуальных методов, в основном это экспертные методы;
- применение методов дискретной оптимизации.
1.2.1. Интеллектуальные системы и методы структурного синтеза
Для задач структурного синтеза применяют следующие интеллектуальные системы и технологии:
Ø решение изобретательских задач;
Ø экспертные системы;
Ø морфологический синтез с использованием паттернов проектирования;
Ø системы поддержки принятия решений (СППР);
Ø интеллектуальный анализ данных (DM - Data Mining).
Решение изобретательских задач. Решение изобретательских задач ведет свое начало с работ Г.С. Альтшуллера по созданию теории решения изобретательских задач (ТРИЗ). Целью ТРИЗ является установление закономерностей изобретательского творчества и их связи с развитием техники. Была разработана система решения изобретательских задач АРИЗ, в которой принятие проектных решений основано на выявлении противоречий (конфликтных условий работоспособности параметров) и их устранении. Для синтеза используются также наборы типовых приемов синтеза решений и библиотеки технологических и физических эффектов. Однако АРИЗ не нашла практического применения в САПР.
Экспертные системы. Экспертная система - интеллектуальная система, предназначенная для решения задач на основе знаний, полученных от экспертов (специалистов в конкретной предметной области) и воплощенных в системе.
В 80-е годы прошлого века был создан ряд экспертных систем в медицине, химии, геологии. Известны экспертные системы технической диагностики, используемые как при изготовлении, так и при эксплуатации оборудования. Имеются примеры применения экспертных систем в САПР. Одним из них является решение задачи автоматизированного синтеза сооружений биохимической очистки сточных вод [15].
Однако широкого распространения в САПР экспертные системы не получили из-за сложностей создания баз знаний, каждая из которых к тому же имеет узкоспециализированный характер.
Паттерны (образцы проектных решений) предназначены для многократного использования. Важным начальным этапом при работе с паттернами является адекватное моделирование рассматриваемой предметной области. Это является необходимым как для получения должным образом формализованной постановки задачи, так и для выбора подходящих паттернов проектирования. Модель системы, построенная в терминах паттернов проектирования, фактически является структурированным выделением тех элементов и связей, которые значимы при решении поставленной задачи.
Системы поддержки принятия решений. Системы поддержки принятия решений представляют собой обширный класс интеллектуальных систем, которые помогают пользователю решать слабо структурированные проблемы на основе имеющихся данных и моделей. Если экспертные системы позволяют воспользоваться опытом и знаниями высококвалифицированных специалистов в достаточно определенных ситуациях, то СППР предназначены для поддержки принятия решения в менее стандартных ситуациях при управлении слабо структурированными объектами. Большинство созданных СППР предназначено для принятия управленческих решений. Имеются СППР, в которых решение задач ищется в виде фактов, правил, процедур, полученных от экспертов, т.е. эти СППР основаны на экспертных системах. В САПР наиболее подходящими являются СППР, управляемые моделями. В них результат достигается с помощью доступа и оперирования математическими моделями и методами дискретной оптимизации. Следовательно, для развития СППР требуется наличие эффективных методов дискретного математического программирования.
Системы Data Mining. Data Mining (DM) — направление в области интеллектуальных систем, связанное с поиском в больших объемах данных скрытых зависимостей и закономерностей. В большинстве случаев к области DM относят задачи:
Ø кластеризации,
Ø классификации,
Ø поиска ассоциаций (взаимозависимостей) между объектами в виде правил или формул (например, регрессионные зависимости),
Ø поиска временных последовательностей – прогнозирование (секвенциальный анализ).
В DM находят применение методы дискретной оптимизации, в том числе генетические алгоритмы, а также искусственные нейронные сети (для решения задач распознавания, кластеризации, прогноза); правила и деревья решений; нечеткая логика; поиск аналогов и прототипов; методы экспертных систем.
1.2.2. Методы дискретного математического программирования
Из обзора интеллектуальных методов структурного синтеза следует, что, во-первых, экспертные системы в САПР достаточно широкого применения не нашли, во-вторых, в СППР и DM поиск проектных решений сводится к задаче оптимизации. Поэтому прогресс в области структурного синтеза проектных решений, прежде всего, связан с развитием методов дискретной оптимизации.
Задачи оптимизации при решении задач структурного синтеза формулируются в виде задач дискретного математического программирования (ДМП):
extr F(X), (1)
X€D
D = { X | W(X) > 0, Z(X) = 0} ,
где F(X) - целевая функция, количественно характеризующая качество проектного решения; W(X), Z(X) — вектор-функции, связанные с представленными в ТЗ требованиями и ограничениями; D — дискретное множество. Вектор управляемых параметров X составляют параметры, определяющие проектное решение. В случае сильно структурированных данных в X входят параметры, имеющие естественное числовое представление. Для применения большинства методов ДМП требуется слабо структурированные данные преобразовать в параметры сильно структурированные.
Поскольку задачи структурного синтеза, как правило, являются NP-полными (или NP-трудными), то точные методы, основанные на полном переборе решений, нереализуемы и нужно использовать методы сокращенного перебора.
Примитивный случайный перебор основан на случайном выборе значений управляемых параметров в области их определения, т.е. выборе точки в пространстве параметров, и расчете целевой функции в этой точке. Проводятся статистические испытания по методу Монте-Карло. В качестве результата решения задачи принимаются значения параметров X в точке с наилучшим значением целевой функции F(X). Поскольку обычно число статистических испытаний N на много порядков меньше мощности множества допустимых вариантов решения, затраты времени на решение оказываются приемлемыми, но вероятность попасть в малую окрестность экстремальной точки крайне мала, поэтому точность решения в большинстве случаев оказывается неудовлетворительной. Поскольку существуют более эффективные методы поиска случайный перебор практически не применяется.
Затраты времени на случайный перебор точек X можно существенно сократить, если ограничить пространство перебора малой окрестностью текущей точки поиска, что и используется в методах локального поиска и поиска с запретами. Найденная наилучшая точка в этой окрестности принимается в качестве новой текущей точки и процесс поиска продолжается вплоть до выполнения условий останова.
Очевидно, что для применения метода требуется, чтобы все элементы вектора X имели числовую форму и пространство поиска было метризовано, поскольку используется понятие окрестности точки. Эти условия выполняются лишь в отдельных случаях задач синтеза. Кроме того, велика вероятность "застревания" траектории поиска в окрестностях локальных экстремумов. Для устранения последнего недостатка применяют метод поиска с запретами (Tabu Search), в котором вводят запреты на повторное исследование точек и учет этих запретов при переходе к шагу исследования окрестности новой точки. Этот прием увеличивает вероятность выхода из локальных экстремумов на траектории поиска.
В методах ветвей и границ множество решений M разбивается на ряд подмножеств Mk (ветвление), и вместо перебора всех элементов этих подмножеств рассчитываются нижние границы L(Mk) минимизируемой целевой функции F(X) в подмножествах Mk. Сокращение перебора возможно в связи с тем, что далее ветвлению подвергается только то подмножество Mk, у которого нижняя граница оказалась наименьшей. Однако если у новых появившихся подмножеств нижние границы окажутся хуже, чем у какого-либо из ранее образованных подмножеств, то придется вернуться к шагу ветвления, на котором было образовано это более перспективное подмножество. При этом метод обеспечивает точное решение задачи, но в худшем случае из-за таких возвратов имеет место полный перебор.
Для применения метода необходимо иметь алгоритм вычисления нижних границ. Если использовать то или иное упрощение задачи (приближенное вычисление нижних границ, ограничение возвратов и т.п.), то метод становится приближенным и за счет потери точности гарантирует приемлемые затраты времени решения.
Наличие среди управляемых параметров предметных переменных, например, таких как тип прибора, форма поверхности и т.п., приводит к необходимости поиска решений в неметризуемых пространствах. В этих условиях зачастую единственным подходом к поиску квазиоптимальных решений оказывается применение эволюционных методов.
В эволюционных вычислениях используются принципы адаптации живых организмов к условиям внешней среды в процессе эволюции.
В настоящее время изучаются и развиваются три группы эволюционных методов – генетические методы (Genetic Algorithms - GA), методы поведения «толпы» (Particles Swarm Optimization - PSO) и методы «колонии муравьев» (Ant Colony Optimization - ACO).
Начало применению генетических алгоритмов для решения задач оптимизации положил Д.Холланд в 1975 г. [16]. Фундаментальный вклад в развитие GA внес Д.Гольдберг [17]. В дальнейшем генетические алгоритмы успешно применялись для различных задач синтеза конструкций, составления расписаний, маршрутизации транспортных средств, компоновки оборудования, раскроя материалов и др.
Алгоритм PSO первоначально был описан применительно к задачам математической биологии в 1987 г. [18]. Сведения об алгоритмах и результатах решения с помощью методов PSO ряда задач оптимизации приведены, например, в [19,20].
Впервые идея использования для решения оптимизационных задач аналогии с поведением колонии муравьев высказана в 1992 г. [21]. Применение методов ACO показано на примерах задачи коммивояжера [22], раскроя и упаковки [23] и др. Обзор методов ACO приведен в [24].
Для применения эволюционных методов к решению конкретной задачи нужно, во-первых, сформулировать множество управляемых параметров X, во-вторых, разработать модель приложения в виде алгоритма вычисления целевой функции F(X), в-третьих, разработать алгоритмическую реализацию эволюционного метода. При этом, учитывая приближенность и статистическую природу этих методов, нужно стремиться к получению высокоэффективных алгоритмов с позиций как точности, так и трудоемкости вычислений.
1.3. Эволюционные методы
1.3.1. Базовый генетический алгоритм
В генетических алгоритмах (ГА) используется следующая терминология:
Ø Ген – управляемый параметр в задаче оптимизации. Применительно к постановке задачи (1) это элемент xi вектора Х. В качестве гена могут использоваться как непосредственно проектные параметры, так и некоторые соответствующие им коды, например, в мультиметодном методе (HCM) ген есть номер метода, с помощью которого рассчитывается значение проектного параметра.
Ø Хромосома – код проектного решения, упорядоченное множество генов или, другими словами, вектор параметров X в постановке задачи оптимизации (1). Синонимами этого термина могут служить слова «строка», «особь», «запись», «фрейм», «кортеж».
Ø Экземпляр хромосомы - значение хромосомы, или упорядоченное множество значений параметров (кодов) xi.
Ø Аллель – значение гена; аллель может быть представлен в виде десятичного или двоичного числа.
Ø Локус – позиция гена в хромосоме.
Ø Функция полезности – целевая функция.
Ø Популяция – множество хромосом при решении некоторой задачи с помощью генетических методов.
Ø Поколение – множество хромосом, зафиксированный в конкретный момент генетического поиска.
Ø Генотип – набор значений генов, представленный в хромосоме. Обычно генотип характеризует множество проектных параметров.
Ø Фенотип – множество значений выходных параметров проектируемого или исследуемого объекта, соответствующих определенному генотипу.
Генетические алгоритмы имитируют эволюционный процесс приближения к оптимальному результату, начиная с некоторого исходного поколения структур, представленных экземплярами хромосом. Этот процесс в базовом ГА является вложенным циклическим вычислительным процессом. Внешний цикл имитирует смену поколений. Во внутреннем цикле формируются члены очередного поколения (рис. 1).
Члены исходного поколения генерируются случайным образом. При этом для каждого гена задана область определения, например, в виде интервала [xmini, xmaxi] или множества значений генов, и эти значения выбираются с равной вероятностью в пределах области определения.
Результатом каждого очередного витка внешнего цикла является новое поколение, о качестве которого судят по экземпляру хромосомы с лучшим значением функции полезности F(X).
Характер приближения к экстремуму обычно таков, что на начальных витках внешнего цикла скорость улучшения целевой функции довольно значительная, но по мере приближения к экстремуму она замедляется и может наступить прекращение улучшения целевой функции на некотором удалении от экстремальной точки. Это явление называют стагнацией. Обычно оно происходит из-за вырождения популяции - потери разнообразия генного материала. Поиск прекращают по исчерпании лимита отведенного времени на решение задачи либо при появлении признаков стагнации, о чем свидетельствует прекращение улучшения целевой функции, наблюдаемое на протяжении нескольких десятков смен поколений.

Рис. 1. Базовый генетический алгоритм
Во внутреннем цикле базового ГА выполняются генетические операторы в следующей последовательности - выбор родителей, кроссовер, мутация, формирование нового поколения.
Выбор пары членов популяции в качестве родителей производится случайным образом среди членов данного поколения. При этом вероятность выбора экземпляров в качестве родителей зависит от значений их функции полезности, т.е. чем лучше значение целевой функции, тем выше должна быть вероятность выбора.
В базовом ГА выбор родителей выполняется в соответствии с правилом, называемым правилом рулетки: вероятность Pk выбора k-го члена популяции в качестве родителя определяется как отношение полезности данного члена к суммарной полезности всех членов популяции. Если целевая функция минимизируется, то
Npop
Pk = (Fmax-Fk) / ∑ (Fmax-Fi)
i=1
где Fk - функция полезности k-го экземпляра, Fmax - максимальное (наихудшее) значение функции полезности среди членов данного поколения, Npop – размер популяции (число хромосом в текущем поколении).
Порождение новых экземпляров хромосом происходит в процессе кроссовера (скрещивания) родительских пар. Кроссовер заключается в разрыве двух выбранных родительских хромосом и рекомбинации образовавшихся хромосомных отрезков, что дает пару хромосом потомков. На рис. 2 представлен пример кроссовера двух хромосом, состоящих из 10 генов, аллели показаны в виде букв. Два верхних экземпляра - родители, два нижних – потомки. Разрыв хромосом произведен после четвертого локуса.
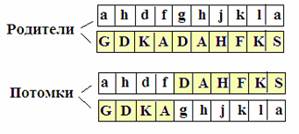
Рис. 2. Кроссовер и рекомбинация хромосомных отрезков
Мутации, т.е. случайные изменения некоторых аллелей, предназначены для расширения пространства поиска. Без мутаций генный материал определяется случайным выбором аллелей при формировании исходного поколения и с высокой вероятностью часть аллелей, составляющих оптимальную хромосому, может оказаться вне доступной части пространства. Например, если в некотором гене в хромосомах начальной популяции оказались сгенерированными только четные числа, то при выполнении операторов кроссовера или селекции нечетные значения появиться не могут.
Мутации устраняют этот недостаток. В базовом ГА мутация каждого гена происходит с заданной вероятностью Рм, эта вероятность обычно выбирается достаточно малой (сотые-тысячные доли). При мутациях значение гена выбирается случайным образом среди множества возможных значений, т.е. в нашем примере произойдет равновероятный выбор среди всех чисел как четных, так и нечетных.
Отбор членов в новое поколение (иногда называемый селекцией) производится среди потомков, полученных в результате кроссовера и мутаций в данном поколении. В базовом ГА в новое поколение включается лучший из двух потомков, порожденных после кроссовера. Внутренний цикл заканчивается, когда окажется сформированным новое поколение, т.е. в нем окажется Npop членов.
Базовый ГА в ряде случаев требует заметных затрат машинного времени. Но главный его недостаток – опасность преждевременного вырождения популяции хромосом, выражающегося в потере разнообразия генного материала. Это вырождение называют стагнацией. Стагнация может наступить вдали от экстремальной точки, что означает низкую точность получаемых решений. К сожалению, в реальных задачах отсутствуют сведения об экстремальном значении целевой функции, поэтому пользователь принимает полученный результат за оптимальный, хотя возможности дальнейшего улучшения решения далеко не исчерпаны. Поэтому главная цель развития ГА заключается в разработке новых генетических методов, обеспечивающих получение решений с повышенной точностью.
1.3.2. Вычислительная эффективность применения генетических алгоритмов. Теорема схем.
Генетические алгоритмы выражают эволюцию популяции хромосом в направлении от начального поколения к окрестностям экстремума. Обоснование этого положения содержится в основной теореме генетического подхода – теореме схем (иначе называемой schemata theorem или теорема шаблонов).
В этой теореме вводится понятие схемы (шаблона), которая определяется как совокупность фиксированных значений генов в определенных локусах. Например, в хромосоме с десятью генами одна из схем Н, включающая единицы в 4-м и 8-м локусах и ноль в 7-м локусе, может быть записана в виде
Н = ***1**01** (2)
где * обозначает позиции, не входящие в схему. Длиной схемы называют расстояние (число межлокусных промежутков) между крайними локусами схемы. В примере (2) длина схемы Н равна 4. Порядком схемы называют число локусов (позиций) схемы. В примере (2) порядок схемы равен 3.
Строительными блоками называют схемы, обладающие высокой приспособленностью, низким порядком и короткой длиной. Приспособленность схемы определяется как среднее от приспособленностей экземпляров строк, которые ее содержат. Процедура отбора выбирает строки с более высокой приспособленностью. Следовательно, строки, которые содержат хорошо приспособленные схемы, выбираются чаще. Кроссовер реже разрушает схемы с более короткой длиной, а мутация реже разрушает схемы с низким порядком, поэтому такие схемы имеют больше шансов переходить из поколения в поколение. В теореме схем отражен тот факт, что ГА экспоненциально увеличивает число экземпляров строительных блоков.
Обозначим число экземпляров схемы Н в поколении с номером t через K(H, t). Введем также следующие обозначения:
Q — множество номеров членов популяции, в хромосомах которых имеется схема H; d(H) — длина схемы H; u(H) — порядок схемы Н; n — длина хромосомы (число генов в хромосоме).
Тогда, если выбор родителей осуществляется по правилу рулетки, то число Kp схем Н, усредненное по Npop актам выбора родителей, в выбираемых родительских хромосомах равно
Npop
Kp = Npop ∑ (Fmax - Fq) / ∑( Fmax - Fi)
qЄQ i=1
Очевидно, что
Npop
∑ Fav(H)=∑ (Fmax - Fq) /K(H, t)
qЄQ i=1
Npop
F0=∑ (Fmax – Fi) / Npop
i=1
где Fav(H) есть усредненная полезность экземпляров со схемой H, а F0 — усредненная полезность всех экземпляров популяции. Поэтому
Kp = K(H, t) Fav(H)/ F0.
При простом одноточечном кроссовере в хромосому потомка схема попадет (т.е. не будет разорвана) с вероятностью
ps= 1 −d(H)/(n-1).
При мутации, происходящей с вероятностью pм для каждой позиции, вероятность сохранения схемы Н, определяемая как (1=pм)u(H), приблизительно равна 1=u(H) pм.
Поэтому вероятность выживания схемы Н равна
ps = (1 - pcd(H)/(n-1)) (1 - u(H) pм) = 1 - pcd(H)/(n-1)- u(H) pм,
где pc — вероятность кроссовера.
Окончательно теорема шаблонов утверждает, что
K(H, t+1) = K(H, t) ps Fav(H)/ F0. (3)
Следовательно, число схем из хромосом перспективных родителей (Fav(H) > F0), имеющих лучшие значения функции полезности, увеличивается в генотипах популяции от поколения к поколению по показательному закону, пока не наступит стагнация, при которой Fav(H) = F0.
Скорость роста K(H, t) тем выше, чем больше Fav(H) и чем меньше длина d(H) и порядок u(H) схемы Н.
Отметим, что в (3) кроссовер рассматривается как фактор, разрушающий шаблоны, и не учитывается возможность формирования в хромосомах потомков шаблонов, отсутствовавших в хромосомах родителей.
1.3.3. Метод «поведения толпы»
В алгоритмах PSO имитируется поведение множества агентов, стремящихся согласовать свое состояние с состоянием наилучшего агента. Положение j-го агента описывается вектором Xj=(xj1,xj2,…xjn), где xji – j-й параметр i-го агента, а состояние i-го агента характеризуется значением целевой функции Yi=F(Xj). Согласование происходит в многошаговом процессе путем корректировки на каждом шаге вектора Xj с учетом положения Xgl наилучшего агента, собственного наилучшего положения X*j на траектории предыдущего перемещения j-го агента в пространстве параметров и фактора случайности.
Базовый алгоритм PSO в случае задачи непрерывной оптимизации заключается в итерационном вычислении значений Xj по формулам:
Vj :=a1 Vj + a2(Xgl - Xj) + a3 (X*j - Xj), (4)
Xj := Xj +Vj;
где Vj – вектор корректировок j-го агента, a1 – коэффициент инерционности в поведении агентов, a2, a3 – случайные коэффициенты, параметры распределения которых подбираются экспериментально.
В отличие от задач непрерывной оптимизации в задаче ДМП пространство параметров может быть неметризовано и тогда формула (4) оказывается неприменимой. Однако использование идей PSO становится возможным, благодаря следующему способу выбора дискретных значений генов: ген xji в формируемой хромосоме Xj выбирается равным i-му гену одной из хромосом-родителей. Выбор конкретного родителя происходит случайным образом. В качестве хромосомы-родителя могут выступать или наилучшая хромосома Xgl всей популяции, или хромосома X*j, наилучшая среди хромосом с номером j всех предшествующих поколений, или j-я хромосома Xj предыдущего поколения. Соответствующие вероятности p1, p2, p3 выбора каждого из этих вариантов подбираются экспериментально. Кроме того, добавляется вариант случайного выбора значения xji с вероятностью p4. При выполнении численных экспериментов, результаты которых приведены ниже, были приняты следующие значения вероятностей p1 = 0,56 p2 =0,40, p3=0,02, p4=0,02.
1.3.4. Метод «колонии муравьев»
В методе «колонии муравьев» (ACO) в случае его использования совместно с описываемым ниже методом комбинирования эвристик новое поколение хромосом на очередном шаге поиска формируется следующим образом. Значение i-го гена, т.е. номер эвристики, которая будет использоваться для i-го шага хромосомы, выбирается из имеющегося набора эвристик на основе информации об успешности применения эвристик на предшествующих шагах. Эта информация представлена в виде матрицы W=[wti] , t=1,2…t, i=1,2…n, t - число используемых эвристик, n – длина хромосомы, равная числу генов в хромосоме, wti – полезность использования t-й эвристики в i-м гене, которая рассчитывается по формуле:
n
wti = (SZ k / SZk)b (5)
k€Cti k=1
где Zk – полезность k–й хромосомы, Cti – множество номеров хромосом, имеющих в i-м локусе ссылку на t-ую эвристику, b - коэффициент, выбираемый в диапазоне 1…3. Полезность Z k определяется как
Z k = b1 (Ymax -Yopt) + (1-b1)(Ymax -Yk),
где b1 € [0,1], Yopt – наилучшее значение целевой функции, полученное на данный момент поиска, Yk - значение целевой функции, соответствующее k–й хромосоме, Ymax – максимальное (наихудшее) значение целевой функции в популяции хромосом на данном шаге.
В соответствии с (5) вероятность выбора t-й эвристики в i-м гене на очередном шаге определяется по формуле
t
Pti = wti/ S wki.
k=1
1.4. Тестовые задачи
Для исследования эффективности ГА предложено несколько вариантов тестовых функций. Известен набор тестовых функций К.ДеДжонга, в котором имеются одно- и многоэкстремальные функции с различным рельефом, а также ряд других наборов [25]. Большинство предложенных наборов включает задачи непрерывной оптимизации сравнительно малого размера. Не отрицая важности и полезности применения таких тестов, следует отметить, что оценивать работу алгоритмов структурного синтеза важно прежде всего на дискретных задачах большого размера.
Большинство задач пространственного синтеза, за исключением задач синтеза формы деталей, оказываются той или иной разновидностью известной математической задачи о рюкзаке. Поэтому в качестве первой основной тестовой задачи для оценки разрабатываемых методов структурного синтеза целесообразно принять задачу о рюкзаке (задачу компоновки) в следующей постановке.
Дано:
Э - множество компонентов (конструктивов) эi, i=1,..n;
В - множество блоков Bj, j= 1,..m;
C - множество связей между компонентами, связь Cik соединяет конструктивы эi и эk.
D - матрица размера n´n, элемент которой Dik равен числу связей между конструктивами эi и эk.
Требуется распределить компоненты по блокам. Множество проектных решений A может быть представлено матрицей Х размера m´n, элемент которой Хji = 1, если конструктив эi включен в блок Bj, иначе Хji = 0. При компоновке следует стремиться к минимизации числа межблочных связей или, что то же самое, к максимизации числа Cвн внутренних для блоков связей.
Поэтому тестовая задача компоновки формулируется следующим образом:
max Cвн(X), (6)
XЄA
m n
где A = {X | å Хji = 1, i= 1,2...n; å Хji £ Vmax, j=1,2...m}, (7)
j=1 i=1
где Vmax - максимальное число элементов, помещающихся в один блок.
Первое из условий в (7) свидетельствует о том, что элемент может быть помещен только в один блок; второе условие - об ограниченном объеме блоков.
При численных экспериментах с задачей (6) нужно иметь возможность в широких пределах варьировать размер задачи, т.е. изменять величины n и m. Но уже при значении n в несколько десятков размер матрицы Х становится чрезмерно большим для ее описания пользователем при задании исходных данных тестовой задачи. Поэтому целесообразно использовать алгоритм динамического формирования тестовых задач, в котором такие параметры задачи, как степень разреженности матрицы D (определяющее число ее ненулевых элементов), множество позиций ненулевых элементов и максимальное значение Cik рассматриваются как случайные величины с задаваемыми в качестве исходных данных диапазонами возможных значений.
Вторая основная тестовая задача отражает особенности задач пространственно-временного синтеза. Это задача синтеза расписаний, имеющая англоязычное наименование JSSP (Job Shop Scheduling Problem).
К исходным данным относятся:
q – число стадий обслуживания каждой работы;
А = {A1,A2,...An} - множество работ;
M ={M1,M2,...Mm} - множество исполнителей (машин или серверов);
P = [Pij] – матрица производительностей машин, где Pij - затраты времени на выполнение работы i на машине j;
C = (C1,C2,...Cm) - вектор цен, где Cj - цена за единицу времени работы машины Mj;
T = (T1,T2,...Tn) - ограничения на время окончания работ, где Ti - предельное время для завершения работы i;
Q - штраф, добавляемый к общим затратам Z при нарушении какой-либо работой соответствующего ей временного ограничения.
Требуется составить расписание, при котором минимизируются затраты на выполнение всех работ с учетом штрафов.
Кроме названных основных тестовых задач, для проверки отдельных аспектов эффективности разрабатываемых методов применялись задачи других типов, например, задача маршрутизации транспортных средств с временными окнами, задача двумерной упаковки, задача синтеза топологии и распределения трафика в вычислительных сетях и др.
2. Генетические алгоритмы
2.1. Разновидности генетических операторов
В ГА имеется ряд альтернативных способов выполнения генетических операторов.
Основные генетические операторы - селекция, кроссовер, мутация. К селекции обычно относят как выбор родительских хромосом для выполнения кроссовера и/или мутации, так и отбор хромосом после кроссовера и мутации с целью формирования нового поколения.

Рис. 3. Варианты селекции
При формировании нового поколения, во-первых, в него после каждого акта кроссовера можно включать не только лучшего из двух потомков, но и вместе с ним лучшего из родителей. Во-вторых, находит применение метод репродукционной группы.
Для гарантированного сохранения в новом поколении лучших генотипов применяют стратегию элитизма. Элитизм – принудительное включение в состав нового поколения наиболее приспособленного представителя предыдущего поколения. Хотя элитизм обеспечивает переход лучшего генного материала из поколения в поколение, он таит в себе опасность преждевременной стагнации.
Основные варианты реализации селекции показаны на рис. 3, где текущее поколение обозначено Птек, новое – Пнов.
В варианте рис. 3,а выбор родителей выполняется по правилу рулетки, в новое поколение включаются или лучший потомок, или лучший потомок и лучший родитель. После отбора Npop экземпляров хромосом старое поколение замещается новым. Возможно использование элитизма.
Рис. 3,б соответствует известному алгоритму Steady State, в котором результаты кроссовера (и/или мутации) сразу замещают худшие особи в текущем поколении.
Рис. 3,в представляет вариант турнирного отбора, в котором родители выбираются из предварительно сформированной репродукционной группы R. Формирование R заключается в создании q подмножеств из случайно выбранных хромосом текущего поколения, в репродукционную группу включают лучших представителей из каждого подмножества. Выбор родителей из R выполняется с равной вероятностью или в соответствии с правилом рулетки.
В варианте турнирного отбора рис. 3,г в репродукционную группу включают всех потомков и всех родителей. После выполнения g актов кроссовера в группе оказывается 4g членов. Среди них для включения в новое поколение отбирается Npop лучших хромосом.
Различают кроссовер одно- и многоточечный по числу разрывов родительских хромосом. На рис. 2 проиллюстрирован кроссовер одноточечный. Особым случаем многоточечного кроссовера является однородный кроссовер, при котором каждый ген в хромосоме-потомке есть результат случайного выбора гена одной из родительских хромосом. Для однородного кроссовера генерируется случайный двоичный вектор длиной n, где n – число генов в хромосоме. Если i-й элемент вектора равен 1, то i-й ген потомка есть i-й ген первого родителя, иначе i-й ген берется от второго родителя.
Возможны случаи, когда гены в хромосоме являются взаимозависимыми и, следовательно, обычные схемы кроссовера могут привести к получению недопустимых хромосом. Примером такого случая может служить задача о назначениях, в которой задано n работ и n исполнителей и требуется назначить на каждую работу одного исполнителя, причем один исполнитель может выполнить только одну работу. Для получения корректных хромосом (проектных решений) в таких ситуациях рекомендуется применение метода PMX (Partially Matched Crossover) [17].
Наряду с классическим кроссовером, находят применение алгоритмы формирования потомков с участием многих родителей [26].
При обычной мутации каждый ген в хромосоме-потомке может изменить свое значение на случайное с вероятностью pм, причем pм остается постоянной в процессе решения задачи. Наряду с этим используют мутации с переменной вероятностью pм. В частности, для снижения опасности преждевременной стагнации целесообразно увеличивать pм, если выбранные родительские хромосомы различаются незначительно (т.е. в них число генов с неодинаковыми аллелями мало). Другая разновидность оператора мутации – макромутация. При макромутациях с вероятностью pм изменяют свои значения группы из k генов, k>1.
Как показывают практические расчеты, существенное влияние на эффективность генетического поиска оказывает выбор типа оператора кроссовера. Выбор может выполняться между одно- и многоточечным кроссовером. Многоточечный кроссовер исследовался еще в начале 90-х годов прошлого столетия. В 1989 г. Д.Сисверда (G.Syswerda) предложил однородный кроссовер [27]. В 1991 г. на эффективность однородного кроссовера указали К.ДеДжонг (K.DeJong) и В.Спирс (W.Spears), объяснившие предпочтительность многоточечного кроссовера (включая однородный) лучшей выживаемостью длинных схем, упомянув также улучшение потенциала рекомбинации [28]. В [29] показано, каким образом потенциал рекомбинации связан с эффективностью многоточечного кроссовера.
2.2. Параллельные и гибридные генетические методы
Генетические алгоритмы могут быть распараллелены, по меньшей мере, двумя способами.
Первый способ относится к параллельному выполнению операций внутреннего цикла базового ГА. Очевидно, что в этом случае имитируется эволюция одной и той же популяции хромосом. Реализация алгоритма целесообразна на компьютере с числом процессоров, не меньшем размера популяции Npop.
Второй способ заключается [30] в имитации эволюции нескольких популяций, периодически обменивающихся между собой частью своих генотипов. Разновидности этого способа определяются расписанием межпопуляционных обменов. В расписании должны быть указаны следующие сведения: а) период автономной эволюции, измеряемый числом смен поколений в популяциях между обменами; б) матрица B обменов, элемент bij которой равен 1, если генный материал передается от популяции i к популяции j, иначе bij=0 ; в) содержание обменов, т.е. список хромосом, передаваемых при обмене от популяции i к популяции j. Например, возможен круговой обмен (bij=1, только если j=i+1, за исключением популяции с максимальным номером j, для которой b1j=1). Генетический алгоритм с межпопуляционными обменами по второму способу находит применение и на однопроцессорных компьютерах.
Если популяции обмениваются своими лучшими представителями, то обычно после нескольких обменов во всех популяциях начинают доминировать генотипы лучшего из поколений, т.е. происходит выравнивание качества генофонда во всех популяциях на уровне лучшей из популяций. Другими словами, результаты применения параллельного ГА приблизительно совпадают с результатами выполнения нескольких попыток решения задачи обычным (непараллельным) способом.
Гибридным называют алгоритм, в котором для поиска экстремума используются идеи двух или более методов оптимизации. Типичным примером гибридного алгоритма является генетический алгоритм с улучшением каждого генерируемого потомка с помощью метода локального поиска. Локальный поиск выполняется посредством макромутаций. Размер макромутаций, т.е. число мутируемых генов, определяет окрестность текущей точки поиска, в которой ищется лучшая точка. Число безуспешных попыток найти такую точку ограничено величиной k. Если найдена точка с лучшим значением функции полезности, то происходит переход в эту точку и вновь допускается поиск с числом попыток, равным k.
Как показали результаты экспериментов, гибридные алгоритмы не имеют заметных преимуществ по точности получаемых решений перед негибридными ГА, в то же время затраты времени на решение могут существенно возрасти.
2.3. Метод комбинирования эвристик
При постановке задач структурного синтеза с помощью эволюционных методов необходимо прежде всего выбрать способ кодирования проектных решений, т.е. способ отображения в хромосоме оптимизируемых параметров.
Непосредственное представление структурных параметров (например, в случае задачи JSSP порядковых номеров работ и номеров используемых машин), во-первых, порождает проблему появления недопустимых хромосом и вытекающую из этого необходимость использования операторов корректировки, во-вторых, излишне удлиняет хромосому, что отрицательно сказывается на эффективности поиска экстремума. Поэтому целесообразно использовать идею отображения в хромосоме информации о синтезируемом объекте в неявной форме, что выполнено в эволюционном методе комбинирования эвристик (HCM – Heuristics Combination Method) [31]. Гены в этом методе представляют не сами структурные параметры, а указывают на способ (метод) определения этих параметров, что дает основание называть HCM также мультиметодным ГА. Так, в случае синтеза расписаний гены должны представлять не номера работ или обслуживающих аппаратов, а правила генерации очередного пункта расписания.
В НСМ исходная задача трансформируется в задачу поиска и использования оптимальной последовательности правил (другими словами, оптимальной последовательности эвристик), используемых в процессе поиска экстремума. Последовательность применения этих правил можно рассматривать как программу структурного синтеза и, с этой точки зрения, HCM можно интерпретировать как разновидность генетического программирования.
Как показывают численные расчеты, применение единственной конкретной эвристики не приводит к удовлетворительным результатам. В то же время использование неодинаковых эвристик на разных шагах синтеза решений порождает множество возможных решений, среди которых имеются варианты со значительно лучшими значениями целевой функции. Поэтому возникает задача поиска оптимальных комбинаций эвристик. Решение задачи оптимального выбора последовательности эвристик и составляет сущность НСМ.
В НСМ аллелями являются не значения проектных параметров, а имена эвристик, используемых для определения этих значений. Выполнение условий корректности хромосом переносится в сами эвристики, что делает собственно эволюционный алгоритм инвариантным к различным задачам. Простой сменой набора эвристик легко осуществляется адаптация имеющихся программ структурного синтеза к особенностям конкретного класса задач.
3. Новые генетические методы
3.1. Смешанный эволюционный метод
3.1.1. Обоснование предпочтительности многоточечного кроссовера
Метод, названный смешанным эволюционным (MMEM - Mixed Mode Evolution Method), является генетическим методом, характеризующимся следующими двумя свойствами: 1) кроссовер является многоточечным; 2) при формировании каждого потомка возможно использование генного материала более чем двух родителей. Эффективность MMEM заключается в лучшем приближении к экстремуму по сравнению с обычными генетическими методами, т.е. в большей точности результатов оптимизации. Обоснованием этого утверждения являются результаты следующего анализа процессов разрушения/генерации шаблонов при рекомбинации хромосомных отрезков.
Теорема схем учитывает наследование схем и их возможное разрушение при кроссовере и мутациях, но не учитывает процессы появления новых схем. Для учета процессов как разрушения, так и генерации схем необходимо дополнить выражение (3) для K(H, t+1) слагаемым, учитывающим вероятность синтеза новых схем.
Рассмотрим ситуацию генерации двухпозиционных схем, состоящих из аллеля A в j-м локусе и аллеля B в (j+1)-м локусе, при многоточечном кроссовере. Обозначим вероятность появления A и B в родительских хромосомах t-го поколения соответственно через pA и pB, а вероятность появления A и B в составе одной и той же родительской хромосомы через pAB. Предположим, что многоточечный кроссовер выполняется путем рекомбинации в хромосомах отрезков X1 и X2 равной длины L. Тогда вероятность появления нового экземпляра схемы HАВ с аллелями A и B в хромосоме-потомке в результате одного акта кроссовера с разрывом после j-го локуса будет равна (pA - pAB)(pB - pAB), а вероятность сохранения схемы HАВ вследствие того, что одна или обе родительские хромосомы уже включают схему HАВ, оценивается как (pA - pAB)pAB + ( pB - pAB) pAB + pAB2. Суммируя эти вероятности, получаем
(pA - pAB)(pB - pAB) + (pA - pAB) pAB +( pB - pAB) pAB + pAB2 = pApB.
Следовательно, в результате Npop актов кроссовера, происходящего с вероятностью Pc, имеем увеличение числа схем по сравнению с результатом, вытекающим из теоремы схем, на величину
NpopPcpApB /L. (8)
Очевидно, что полученный результат для двухпозиционных схем справедлив и для многопозиционных схем, если под A и B понимать схемы, находящиеся по разные стороны от линии разрыва хромосом и длины которых не превосходят L. При этом вероятность pA должна быть определена как K(А)Fav(А)/F0, аналогично определяются pB и pAB.
Скорректированное с учетом (8) выражение теоремы схем принимает вид
K(HАВ,t+1)={K(HАВ,t)(1-Pc/L)Fav(HАВ)/F0+NpopPcpApB/L}(1- u(HAB) Pм). (9)
Выражение (9) свидетельствует о немонотонном влиянии числа разрывов родительских хромосом (или длины фрагментов L) на эффективность алгоритма. Следовательно, имеется некоторый оптимальный диапазон значений L. Этот результат положен в основу разработанного смешанного эволюционного метода, сокращенно обозначаемого MMEM (Mixed Mode Evolution Method).
3.1.2. Варианты смешанного эволюционного метода
Специфика MMEM отражена главным образом в блоке формирования хромосом для следующего поколения. Родительские хромосомы при кроссовере делятся на фрагменты одинаковой длины и эти фрагменты рекомбинируют. Параметрами, характеризующими особенности применяемого метода, являются длина фрагментов, на которые разделяются родительские хромосомы, параметр g, указывающий наличие или отсутствие кроссовера внутри фрагментов (g € {да, нет}), число хромосом-родителей у каждой формируемой хромосомы.
В первом варианте кроссовера используются две родительские хромосомы A и B, разделяемые на фрагменты длины L. Потомки образуются из чередующихся фрагментов родителей, пример дочерней хромосомы показан на рис. 4, где L=5, а наверху рисунка отмечено, из какой хромосомы (A или B) взят фрагмент. В каждом акте формирования потомков значения L являются случайными.
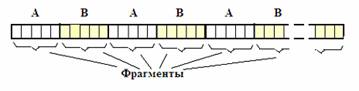
Рис. 4. Структура хромосомы в первом варианте формирования потомка
Второй вариант кроссовера отличается от первого тем, что при использовании двух родителей вводится дополнительный кроссовер внутри каждого фрагмента, причем случайно выбираемые точки разрыва отделяют участки хромосом, взятые от разных родителей (рис. 5).
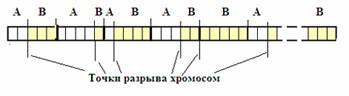
Рис. 5. Структура хромосомы во втором варианте формирования потомка
Третий и четвертый варианты кроссовера аналогичны первому и второму, но отличаются от них тем, что в формировании потомка может участвовать более двух родителей (полигамность). Потомок формируется из фрагментов хромосом, случайно выбираемых в соответствии с их вероятностями qj, рассчитанными в процедуре «Определение перспективности членов популяции».
Частными случаями предложенной процедуры формирования потомков являются реализации эволюционных методов ГА, ACO и PSO.
Так, второй вариант при длине L, равной длине всей хромосомы, соответствует одноточечному ГА. Тот же вариант, но при L=1, близок к ГА с однородным кроссовером. Третий вариант при L=1 соответствует методу ACO. Метод PSO имеет место, если L=1, а в качестве родителей при формировании j-го потомка преимущественно используются две хромосомы: глобально рекордная (с лучшим значением целевой функции среди всех хромосом популяции) и локально рекордная (с лучшим значением целевой функции среди j-х членов всех предыдущих поколений).
3.2. Метагенетический метод
Эффективность применения ГА, оцениваемая прежде всего степенью приближения результатов решения к оптимальным значениям, не всегда оказывается удовлетворительной. Обычно повышение эффективности стремятся достичь на основе применения новых алгоритмов выполнения генетических операторов или с помощью метода комбинирования эвристик. В свою очередь, эффективность HCM зависит от правильности выбора совокупности используемых при поиске эвристических правил.
К сожалению, априорный выбор наиболее эффективных алгоритмов выполнения генетических операторов и эвристических правил, как правило, невозможен. Поэтому на практике перед собственно решением задачи выполняют пробные решения с варьированием конкурирующих алгоритмов и совокупностей эвристик. Однако такие предварительные решения существенно увеличивают и без того большие затраты машинного времени на получение искомых результатов и потому возможны лишь в отдельных случаях. Поэтому целесообразен автоматический выбор типов генетических операторов и/или эвристик в процессе решения задачи, т.е. использование адаптивных ГА.
Известны примеры адаптивных ГА. Однако авторы таких алгоритмов, как правило, ограничивались рассмотрением отдельных адаптируемых параметров, например, в [32] предложена адаптация оператора мутации, в [33] использована автоматическая настройка вероятностей мутации и кроссовера.
Ниже рассмотрен метод автоматического выбора набора эвристик и адаптации набора параметров алгоритма к условиям задачи в процессе ее решения, т.е. выбора рациональной конфигурации ГА. Как основная задача оптимизации проектных параметров, так и адаптация параметров алгоритмов выполняются генетическими методами.
Предлагаемый метод можно рассматривать как разновидность генетического программирования [34].
Метод обеспечивает следующие преимущества:
1. Автоматический выбор эвристик. Например, априорно выбранные неудачные эвристики будут исключены из используемого набора.
2. Отсутствие априорной информации о предпочтительных значениях параметров не является критичным, так как алгоритм автоматически определяет параметры генетического алгоритма.
3. Адаптация происходит к особенностям этапа поиска. Например, в период стагнации намного предпочтительнее случайные операторы выборки и кроссовера, так как они могут вывести алгоритм из состояния стагнации, а на ранних этапах поиска эффективнее такие операторы селекции, как метод рулетки.
Последовательность применения генетических операторов в основном ГА может быть представлена в виде псевдокода следующим образом:
GENETIC ALGORITHM
begin
create initial population of fixed size;
do{
select parent1 and parent2 from population P1;
offspring = crossover(parent1, parent2);
mutation(offspring);
if suited(offspring) then
replace(population, offspring);
} until stopping condition;
report the best answer;
end.
В предлагаемом методе дополнительно к основной популяции P1, в генах которой хранятся номера эвристик для выполнения очередного шага синтеза решения, вводится популяция P2, состоящая из хромосом, в генах которых хранятся конфигурационные параметры для основного генетического алгоритма, т.е. номера методов кроссовера, селекции и мутации, вероятности кроссовера, мутации и выбора эвристик при использовании HCM.
Таким образом, метагенетический алгоритма принимает вид (при формировании исходных популяций аллели всех хромосом выбираются случайным образом):
META-GENETIC ALGORITHM
begin
create initial population P1;
create initial population P2;
do{ ADDITIONAL ALGORITHM STEP(population P2);
BASIC ALGORITHM STEP(select configuration from P2);
} until stopping condition;
//report the best answer;
end.
Процедура ADDITIONAL ALGORITHM STEP имитирует эволюцию популяции P2:
ADDITIONAL STEP (P2)
begin
for i = 1 to n2
{select parent1 and parent2 from P2;
offspring = crossover(parent1, parent2);
mutation(offspring);
offspringfitness = SIMPLE_STEP(offspring);
replace(P2,offspring);
}
end.
Оценка хромосом из популяции P2 выполняется в соответствии со следующим алгоритмом:
SIMPLE_STEP ( config )
begin
config→select parent1 and parent2 from population P1;
offspring = config→crossover(parent1, parent2);
config→mutation(offspring);
return evaluate(offspring);
end.
Другими словами, для каждой хромосомы популяции P2 выполняется процедура SIMPLE_STEP, в которой из популяции P1 выбираются (config→select) родители. В результате их скрещивания (config→crossover) появляется потомок (offspring) – новая хромосома, которая далее мутирует (config→mutation). Оценка полезности потомка является также оценкой полезности данной конфигурации config.
Процедура BASIC ALGORITHM STEP имитирует эволюцию основной популяции P1:
BASIC ALGORITHM STEP(config)
begin
for i = 1 to n1 {
config→select parent1 and parent2 from population P1;
offspring = config→crossover(parent1, parent2);
config→mutation(offspring);
if suited(offspring) then
replace(P1, offspring);
}
end.
Выбор конфигурации из популяции P2 для выполнения процедуры BASIC ALGORITHM STEP основного алгоритма производится с помощью метода турнирной селекции.
3.3. Циклический генетический метод
Стагнация наступает при вырождении популяции. Для ее предотвращения обычно используют макромутации и/или увеличение вероятности мутации. Однако по мере приближения к малым окрестностям экстремума (а именно тогда и наступает стагнация) обычные макромутации становятся малоэффективными. Это связано с тем, что функция F(X) мутированной хромосомы оказывается значительно хуже, чем у других хромосом популяции, мутированная хромосома выпадает из числа возможных родителей и, следовательно, не может вывести популяцию из состояния стагнации. Если же попытаться уйти из этого состояния, выполнив мутации большинства генов у всех хромосом, то мутированные хромосомы смогут участвовать в генерации потомков, поскольку полезности всех членов популяции становятся сопоставимыми. Но при столь значительных мутациях теряется накопленный полезный генный материал и поэтому после макромутации поиск начинается вновь с исходных позиций.
Для того чтобы макромутации были эффективными, необходимо выполнение двух условий:
1. Сохранение накопленного генного материала;
2. Начальная полезность всех хромосом после макромутаций должна быть соизмеримой.
Совместить эти два противоречивых требования удалось в методе, названном циклическим ГМ. Циклический ГМ создан в рамках смешанного эволюционного метода. Его сущность поясняет рис. 7
В соответствии с циклическим методом каждая хромосома текущего поколения может при макромутациях породить двух потомков. В хромосому первого потомка переписываются нечетные фрагменты, а гены четных фрагментов получают случайным образом сгенерированные аллели. В хромосоме второго потомка сохраняются фрагменты родителя с четными номерами, а нечетные фрагменты заполняются случайными значениями.
Макромутации повторяются периодически через W смен поколений, называемых циклами, где W – число смен поколений, после которых вероятно появление признаков стагнации. Поскольку за счет 50% заполнения генов случайными значениями число хромосом после макромутаций увеличивается вдвое, в операции макромутации участвует и далее используется лишь половина хромосом предыдущего поколения.
После каждой макромутации целевая функция резко ухудшается, но за счет сохранения полезных схем в новом цикле наблюдается ее ускоренное улучшение, причем велика вероятность, что это улучшение приведет траекторию поиска в меньшую окрестность экстремума (или на более удачный уровень стагнации), чем это было в предыдущем цикле.
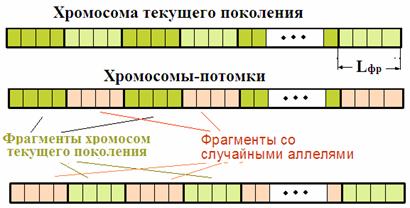
Рис. 7. Макромутации в циклическом генетическом методе
.
4. Экспериментальная оценка эффективности новых генетических методов
4.1. Многоточечность и полигамность
4.1.1. Оценка эффективности смешанного эволюционного метода
В этой части статьи приведены результаты экспериментов по оценке эффективности многоточечности и полигамности, составляющими основу предложенного смешанного эволюционного метода, в сравнении с известными генетическими методами. В качестве тестовых использовались задачи, рассмотренные в части 1. Было принято следующее лаконичное обозначение методов:
имя метода – число точек разрыва хромосом при кроссовере (число
родителей).
Если именем одноточечного базового ГА является CGA (Classic Genetic Algorithm), то его обозначение будет CGA-1(2). В смешанном эволюционном методе фигурируют m точек разрыва (multipoint crossover) и m родителей (multi parents), поэтому MMEM будет обозначаться CGA-m(m), если гены непосредственно являются искомыми параметрами задачи, или HCM-m(m), если гены обозначают номера эвристик для расчета искомых параметров.
Выполненное исследование потенциала рекомбинации позволяет сделать вывод о наличии оптимальных значений длин фрагментов L, на которые разделяются хромосомы при кроссовере. Для подтверждения этого вывода было проведено экспериментальное исследование зависимости функций полезности от L на примерах нескольких задач.
Одной из наиболее сложных для решения NP-трудных задач является многостадийная задача синтеза расписаний (JSSP). В этой задаче при применении HCM используются эвристики, состоящие из правил двух групп. Правило первой группы служит для выбора очередной работы, назначаемой на исполнение. Правило второй группы содержит алгоритм выбора машины для этой работы. Два основных использованных правила первой группы:
Ø выбирается работа с наименьшим предельным временем выполнения Ti;
Ø правило «первым пришел – первым обслужен» (FIFO).
Правила второй группы:
Ø выбирается наиболее производительная машина;
Ø выбирается машина с наименьшей ценой обслуживания.
Сочетание правил двух групп дает четыре эвристики.
Ранее отмечено, что снижение эффективности генетического поиска происходит из-за явления преждевременной стагнации. Это явление исследовалось на применении методов HCM -1(2) и HCM -20(m) к задаче синтеза расписаний со следующими исходными данными число стадий обслуживания работ q=4 стадии, число работ n=105, число машин m=15. Результаты двух вариантов решения задачи при применении каждого из сравниваемых методов приведены в табл. 1, где N – число разрывов хромосом при кроссовере (отметим, что длина хромосомы в данной задаче равна q*n=420), Evals – число оценок целевой функции. Результаты показывают, что при многоточечном кроссовере вероятность преждевременной стагнации уменьшается, соответственно удается заметно ближе подойти к точке экстремума.
Табл. 1
|
Evals |
270 |
20т |
30т |
40т |
50т |
75т |
100т |
125т |
|
N=20 |
22570 |
22293 |
22121 |
21963 |
21901 |
21834 |
21821 |
21811 |
|
N=20 |
23498 |
22147 |
22073 |
21970 |
21850 |
21798 |
21789 |
21781 |
|
N=1 |
22570 |
22145 |
22126 |
22118 |
22118 |
22118 |
22118 |
22118 |
|
N=1 |
23498 |
22134 |
22119 |
22100 |
22099 |
22083 |
22072 |
22072 |
Назовем коэффициентом разнообразия долю генов, имеющих неодинаковые значения в хромосомах родителей в очередном акте кроссовера. На рис. 8 представлена зависимость коэффициента разнообразия r от номера поколения. На рисунке светлыми точками обозначены значения r, полученные в некоторых случайно выбранных актах кроссовера при применении смешанного метода HCM-20(m), а темными точками – аналогичные значения, полученные при применении одноточечного кроссовера HCM-1(2). Рисунок иллюстрирует заметно меньшую предрасположенность MMEM к ранней стагнации.
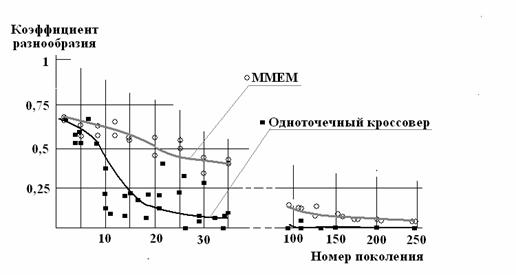
Рис. 8. Иллюстрация вырождения популяции с ростом числа поколений
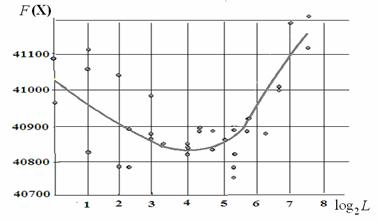
Рис. 9. Зависимость результатов решения задачи синтеза расписаний
от длины фрагментов L
Выше было приведено теоретическое обоснование наличия оптимальных значений длин фрагментов L в смешанном эволюционном методе. Для подтверждения теоретических результатов были проведены эксперименты по определению оптимальных значений L.
На рис. 9 представлены результаты решения задачи синтеза многостадийных расписаний с 4 стадиями, 200 работами и 15 машинами с помощью метода HCM-m(m). Точки соответствуют отдельным вариантам решения, кривая отображает усредненную зависимость целевой функции от размера фрагмента L.
Полученные результаты позволяют сделать вывод: длина фрагментов L влияет на эффективность поиска. Для HCM-m(m) в задаче JSSP оптимальные значения L находятся в диапазоне {5, 40} при общей длине хромосомы, равной 800. Следовательно, однородный и одноточечный кроссоверы не относятся к лучшим вариантам ГА.
Аналогичные результаты были получены при решении других тестовых задач. Рис. 10 иллюстрирует результаты решения задачи маршрутизации транспортных средств с временными окнами (VRPTW), в которой хромосомы содержат по 40 генов, а рис. 11 – результаты решения задачи синтеза топологии и распределения трафика (СТРТ) в вычислительной сети с хромосомами длиной в 276 генов. В обоих случаях использовался метод HCM-m(m).

Рис. 10. Зависимость результатов решения задачи маршрутизации транспортных средств с временными окнами от длины фрагментов L

Рис. 11. Зависимость результатов решения задачи синтеза топологии сети и распределения трафика от длины фрагментов L
Похожие результаты получены при экспериментах с задачей компоновки. Использовались следующие исходные данные: число элементов (конструктивов) n=200, число блоков m=20, ограничение на максимальное число конструктивов в одном блоке V=16, размер популяции Npop=50, вероятность мутации pм=0,01. В качестве максимизируемой целевой функции использовалось суммарное число связей, замыкающихся внутри блоков. В случае нарушения ограничения функция полезности уменьшалась на величину штрафа F=-50, умноженную на число сверхлимитных конструктивов.
Матрица связей конструктивов формировалась автоматически: общее число ненулевых элементов матрицы определялось как 0,04n2, координаты ненулевых элементов (номера строк и столбцов) выбирались случайно в диапазоне от 1 до n, а элементами матрицы являлись случайные числа, равномерно распределенные в диапазоне [1,6]. Формирование заканчивалось преобразованием матрицы в симметрическую. Использование алгоритма автоматического формирования матрицы связей позволило выполнять эксперименты с задачами, в которых общее число элементов матрицы составляло десятки миллионов.
Результаты расчетов с помощью метода CGA-m(m) представлены в виде точек на графике рис. 12. Отдельные точки графика отображают значения функции полезности F(X), полученные после 2000 смен поколений (около 100000 обращений к процедуре расчета функции полезности) при разных значениях длин фрагментов. Показанная на рисунке кривая – сглаженная зависимость усредненных значений F(X) от log2L. Крайние правые точки соответствует одноточечному кроссоверу, крайние левые точки – однородному кроссоверу. Особенность полученных результатов – наличие двух максимумов на графике функции. Приемлемым окрестностям этих максимумов соответствуют значения L в диапазоне от 1 до 50 (для n=200), в этот диапазон попадает и однородный кроссовер. Как и в предыдущих примерах, одноточечный кроссовер оказывается малоэффективным.
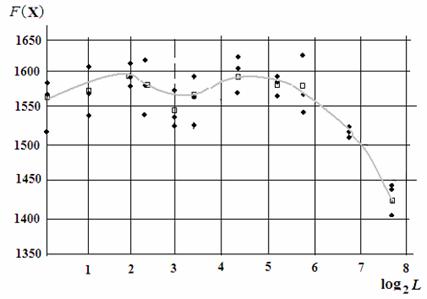
Рис. 12. Зависимость результатов компоновки от длины фрагментов L
Интерес представляет сравнение смешанного эволюционного метода с методами PSO и ACO. Результаты такого сравнения приведены на рис. 13, где Delta есть разность между полученным и наилучшим известным результатом решения тестовой задачи синтеза многостадийных расписаний с 105 работами. Эти результаты свидетельствуют о преимуществе ММЕМ перед другими сравниваемыми методами.
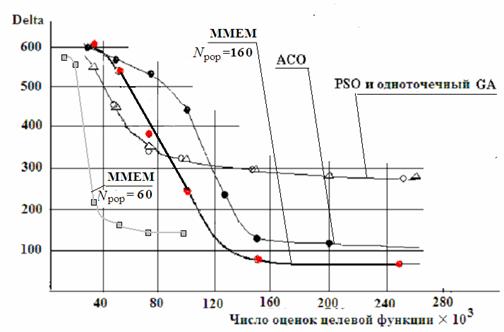
Рис. 13. Сравнение результатов решения задачи синтеза расписаний различными генетическими методами
4.1.2. Оценка эффективности метода комбинирования эвристик
Сопоставлялись следующие методы:
Ø случайного перебора (RC),
Ø одноточечный базовый ГА (CGA-1(2)),
Ø многоточечный ГА (CGA-m(m)),
Ø сочетание методов комбинирования эвристик и смешанного (HCM-m(m)),
Ø метод комбинирования эвристик с двумя родителями в операции кроссовера (HCM-m(2)).
В задаче компоновки случайный поиск RC на основе метода Монте-Карло оказался неконкурентоспособным. После 150000 испытаний значение Zmax целевой функции в лучшем из них оказалось равным 419 при классической структуре хромосомы и 472 при использовании комбинирования эвристик, при этом выполнить ограничение на число конструктивов в блоке не удалось, столь малые значения целевой функции объясняются наличием штрафов.
В рамках HCM необходимо использовать совокупность эвристических правил. Для задачи компоновки требуются две группы правил [27]. Первая группа включает правила выбора очередного пакуемого конструктива, вторая группа – правила выбора блока для очередного конструктива.
Примеры правил первой группы:
S1 - выбирается конструктив, которому соответствует максимальный элемент в матрице D;
S2 - выбирается конструктив k с максимальной числом связей с другими конструктивами, т.е. с максимальной суммой элементов в k-й строке матрицы D (в этом и предыдущем правилах строки и столбцы уже распределенных конструктивов не учитываются);
S3 - выбирается конструктив с максимальным числом связей с уже распределенными конструктивами.
Примеры правил второй группы:
Q1 - выбирается минимально загруженный блок;
Q2 - выбирается максимально загруженный блок из числа не полностью загруженных блоков;
Q3 - выбирается блок, имеющий максимальное число связей с распределяемым конструктивом.
Пару правил Si и Qj называют эвристикой Эij. В случае применения приведенного списка правил возможное число эвристик 3 × 3 = 9. Очевидно, что список используемых правил может быть как расширен, так и сужен. В последнем случае для поддержания вариативности поиска на должном уровне следует сочетать комбинирование эвристик с классическим ГА.
В серии экспериментов с задачей компоновки комбинирование эвристик использовалось в сочетании с классическим ГА следующим образом. Первые 2/3 генов хромосомы соответствовали классическому ГА, значение i-го гена равно номеру блока, в который будет помещен i-й конструктив. Последняя треть генов соответствует HCM, значение i-го гена есть номер эвристики, согласно которой выбирается блок для i-го конструктива. Использовались две эвристики – Q2 и Q3.
В табл. 2 представлены значения целевой функции Zmax, усредненные по нескольким вариантам решения задачи компоновки с помощью методов CGA-m(m) и HCM-m(m) при различных значениях длин L фрагментов и с исходными данными n=200, m=20, V=41. Результаты фиксировались после 1000 смен поколений, что соответствует приблизительно 50000 обращений к процедуре расчета целевой функции. Жирным шрифтом выделены лучшие значения целевой функции при каждом значении длины фрагментов L. Отметим, что число точек разрыва хромосом при больших L примерно равно 2n/L – 1, уменьшаясь при малых L до значений n/L – 1.
Табл. 2
|
L |
200 |
20 |
8 |
5 |
4 |
1 |
|
CGA-m(m) |
1966 |
2081 |
2190 |
2158 |
2184 |
2128 |
|
HCM-m(m) |
1977 |
2166 |
2233 |
2258 |
2350 |
2195 |
|
HCM-m(2) |
1984 |
2320 |
2195 |
2238 |
1698 |
1639 |
Результаты экспериментов позволяют сделать следующие выводы:
1. Метод комбинирования эвристик HCM-m(m) превосходит по эффективности метод CGA-m(m) с обычным кодированием хромосом.
2. Смешанный генетический метод HCM-m(m) с многими родителями (полигамность) превосходит по эффективности метод HCM-m(2), в котором при кроссовере происходит скрещивание генов только двух родителей.
3. В случае метода HCM-m(2) наблюдалось заметное снижение эффективности при малых L со смещением оптимальных длин фрагментов в сторону больших значений.
Преимущества метода комбинирования эвристик имеют место и в других задачах. Так, в работе [5] обобщен богатый опыт решения задач раскроя и упаковки и отмечено, что при больших размерах задач (250 элементов и более) мультиметодный алгоритм, т.е. HCM, находится вне конкуренции.
Поскольку перед решением новой задачи пользователю неизвестны оптимальные значения L, целесообразно использовать смешанный эволюционный метод с набором различных значений длин фрагментов. Так, применение метода HCM-m(m) с набором значений L={4, 5, 8}, выбираемых случайно, позволило в трех прогонах последней задачи получить результаты Zmax={2311, 2267, 2241}. При наборе L={4, 8, 20} получены результаты Zmax={2310, 2258, 2249}.
4.2. Адаптивность
Оценка эффективности метагенетического алгоритма проводилась на примере следующей разновидности тестовой задачи синтеза расписаний JSSP. Задано:
· Множество работ A={A1, A2, … An}, где каждая работа Ai последовательно проходит q стадий обслуживания;
· На каждой стадии имеется mk машин k€[1:q], общее число машин m=Smk;
· Для обслуживания работы Аi на стадии k, выбирается одна из mk машин;
· Одновременно на одной машине может обслуживаться не более одной работы, начатое обслуживание не прерывается;
· Все работы распределены по типам и, если соседние во времени исполнения работы, обслуживаемые на j-й машине, относятся к разным типам, то j-я машина должен пройти переналадку;
· Задана матрица производительностей P, элемент Pij равен времени обслуживания i-й работы на j-й машине;
· Для каждой машины задана матрица переналадок E, элемент которой Eir равен времени переналадки машины при переходе с обслуживания работы i-го типа на обслуживание работы r-го типа;
· Заданы цены единицы времени обслуживания и переналадки каждой машины (соответственно Cj и Rj);
· Заданы ограничения на сроки выполнения каждой i-й работы: «мягкие» Di и «жесткие» Ti ограничения, причем Ti> Di, из-за нарушения сроков налагаются штрафы G1 и G2, соответственно, G2 >> G1.
Требуется получить расписание, минимизирующее общие затраты, складывающееся из штрафов, затрат на обслуживание всех работ на всех стадиях и затрат на переналадки всех машин.
В экспериментах принято: число работ 94, число машин 15, размер популяции 200. Чтобы показать адаптационные возможности метагенетического алгоритма, в исходный набор было включено шесть эвристик Э1-Э6 без предварительной оценки их эффективности.
Усредненные по нескольким вариантам расчета зависимости целевой функции F(X) от числа evals обращений к процедуре ее вычисления показаны на рис. 14. Как видно из данных рис. 15, где Pэ – вероятность выбора эвристики, в процессе решения осуществлялась автоматическая настройка на использование рациональных эвристик.
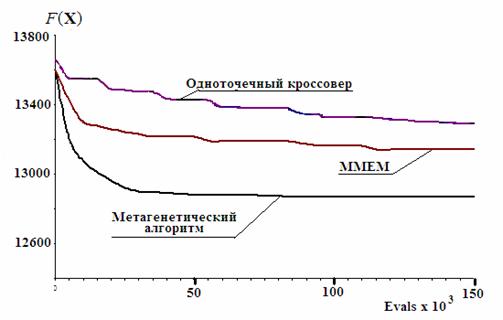
Рис. 14. Сравнительные результаты поиска разными методами
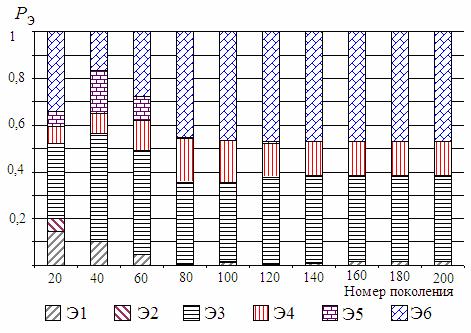
Рис. 15. Изменения вероятностей выбора эвристик в процессе поиска
Эксперименты показали, что метагенетический алгоритм обеспечивает результат более точный по сравнению с результатами применения неадаптивных генетических алгоритмов в среднем на 7-10%.
4.3. Предотвращение преждевременной стагнации
Для иллюстрации повышения эффективности циклического генетического метода (ЦГМ) были выполнены эксперименты с тестовой задачей синтеза расписаний со следующими исходными данными: число работ 105, число стадий 4, число машин на стадиях {4, 4, 4, 3}. На рис. 16 представлены результаты расчетов - зависимости целевой функции F(X) от номера поколения при применении смешанного эволюционного метода HCM-m(m) и ЦГМ с макромутациями через 120 поколений. Как видно на рис. 15, на первых четырех циклах происходило улучшение целевой функции. Причем стагнация в случае HCM-m(m) наступила на уровне F(X)=21751, а в случае ЦГМ на втором, третьем и четвертом циклах достигнуты значения F(X) 21734, 21716 и 21676.
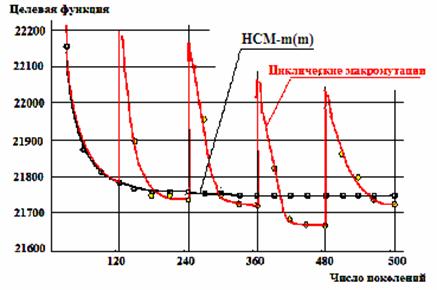
Рис. 16. Результаты решения задачи синтеза расписаний
Циклический метод, хотя и незначительно, но показал преимущества перед непрерывной эволюцией также в задаче компоновки с исходными данными: число компонентов n=200, число блоков m=20, вместимость блоков Vmax=16. В табл. 3 в строке «ЦГМ» представлены усредненные (по нескольким вариантам решения задачи) результаты, полученные в конце циклов, каждый продолжительностью в 500 поколений. Для сравнения в строке «Без циклов» приведены усредненные значения целевой функции, полученные без использования ЦГМ.
Табл. 3
|
Число поколений |
500 |
1000 |
1500 |
2000 |
3000 |
4000 |
5000 |
|
ЦГМ |
1453 |
1507 |
1559 |
1577 |
1616 |
1643 |
1661 |
|
Без циклов |
1453 |
1502 |
1543 |
1565 |
1607 |
1628 |
1636 |
Заключение
Рост сложности технических систем и устройств стимулирует развитие методов структурного синтеза проектных решений. Важной составляющей этого развития становится все более широкое применение в современных САПР интеллектуальных технологий. Эволюционные методы вычислений относятся к интеллектуальным технологиям, непосредственно ориентированным на синтез проектных решений.
Эволюционные вычисления – еще довольно молодое направление в интеллектуальных системах. Проблемы, которые предстоит решать и которые в определенной мере затронуты в данной работе, - это проблемы повышения точности и сокращения затрат вычислительных ресурсов на решение задач с помощью генетических алгоритмов. Есть основания полагать, что эволюционные методы в сочетании с другими методами интеллектуализации процессов проектирования и управления смогут обеспечить решение возникающих проблем создания новых технических изделий.
Литература
- Овчинников В.А. Алгоритмизация комбинаторно-оптимизационных задач при проектировании ЭВМ и систем. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2001. – 288 с.
- Системы автоматизированного проектирования в радиоэлектронике: Справочник / Под ред. И.П.Норенкова. – М.: Радио и связь, 1986. – 368 с.
- Теория и методы автоматизации проектирования вычислительных систем / Под ред. М.Брейера. – М.: Мир, 1977. – 282 с.
- Devis L., Cox A. A genetic algorithm for survivable network design/ Proc. of 5th International Conference on Genetic Algorithms, Morgan Kaufmann Publishers, San Mateo, California, 1993.
- Мухачева Э.А., Валеева А.Ф., Картак В.М., Мухачева А.С. Модели и методы решения задач ортогонального раскроя и упаковки // Приложение к журналу «Информационные технологии», № 5, 2004. – 32 с.
- Кукин В.Д. Эволюционная модель для решения потоковой задачи Штейнера. - Методы математического моделирования и информационные технологии. Труды ИПМИ КарНЦ РАН. Петрозаводск, 2004, в. 5, с. 200 – 211.
- Ли К. Основы САПР (CAD/CAV/CAE). – СПб: Питер, 2006. – 580 с.
- Овчинников В.А. Эволюционно-генетический подход к синтезу передней части кузова легкового автомобиля // Информационные технологии, 2005, № 9, стр.36-38..
- Kapsalis A., Chardaire P., Rayward-Smith V., Smith G. The Radio-link Frequency Assignment Problem: a Case Study Using GA. AISB Workshop on Evolutionary Computing, Springer, 1995.
- Писаренко Г.К. Алгоритмы частотного планирования в телекоммуникационных системах радиосвязи // Информационные технологии, 2000, № 7.
- Giffler B., Tompson G.L. Algorithms for Solving Production-Scheduling problems // Operational Research, 12, # 2. 1964/ P/305-324.
- Btuns R. Direct Chromosome Representation and Advanced Genetic Operators for Production Scheduling // Proc. of 5th Int. Conf. on GA, Morgan Kaufmann Publ., 1993.
- Kobayashi S., Ono I., Yamamura M. An Efficient Genetic Algorithm for Job Shop Scheduling Problem // Proc. of 6th Int. Conf. on GA, Morgan Kaufmann Publ., 1995.
- Blanton J., Wainwright R. Multiple Vehicle Routing with Time and Capacity Constraints Using Genetic Algorithms// Proc. of 5th Int. Conf. on GA, Morgan Kaufmann Publ., 1993. P.452-460.
- Автоматизированный синтез сооружений биохимической очистки сточных вод / ОАО «Пигмент»,
http://www.gaps.tstu.ru/win-251/lab/sreda/ope/ob_ecol_html/avtom.html
16. Holland J. Adaptation in Natural and Artificial Systems. – Univ. of Michigan Press, 1975.
- Goldberg, D. E. Genetic Algorithms in Search, Optimization, and Machine Learning. - Addison-Welsey, 1989.
18. Deneubourg J.-L., Goss S., Pasteels J.M., Fresneau D. and Lachaud J.-P. Self-organization mechanisms in ant societies (II): learning in foraging and division of labor. In: From Individual to Collective. Behavior in Social Insects. - Basel: Birkhauser, 1987.
- Eberhart, R. C., and Kennedy, J. A New Optimizer Using Particles Swarm Theory, Proc. Sixth International Symposium on Micro Machine and Human Science. // IEEE Service Center, Piscataway, 1995.
20. Eberhart, R. C., Dobbins, R. W., and Simpson, P. Computational Intelligence PC Tools. - Boston: Academic Press , 1996.
- Dorigo M. Optimization, Lеarning and Natural Algorithms. PhD thesis, Dipartimento di Electronica. - Politecnico di Milano, 1992.
- Dorigo M., Gambardella L. Ant Coloony for Traveling Salesman Problem. - Bruxelles: TR/TRIDIA/1996-3
- Валеева А.Ф. Применение метаэвристики муравьиной колонии к задачам двухмерной упаковки //Информационные технологии, 2005, № 10.
- Dorigo M., Caro G., Gambardella L. Ant Algorithms for Discrete Optimization. //Artificial Life, v.5, 1999, # 3.
- Genetic Algorithms (Evolutionary Algorithms): Repository of Test Functions. - http://www.cs.uwyo.edu/~wspears/functs.html
- A.E.Eiben, P-E.Raue, Zs.Ruttkay. Genetic Algorithms with Multi-parent Recombination. In Proc. of the 3d Conf. on Parallel Problem Solving from Nature, Springer-Verlag, 1994.
- Syswerda G. Uniform Crossover in Genetic Algorithms, Proc. 3rd Int. Conf. on Genetic Algorithms, Morgan Kaufmann Publ., 1989.
- De Jong K.A., Spears W.M.. A Formal Analysis of the Role of Multi-point Crossover in Genetic Algorithms. Annals of Mathematics and Artificial Intelligence, 1992.
- Норенков И.П., Арутюнян Н.М. Смешанный эволюционный метод // Информационные технологии, 2007, № 1.
- Goodman E., Punch W. New Technologies to Improve Coarse-Grain Parallel GA Performance // CAD-95 XXII Int. School and Conf. on CAD, Part 2, Yalta-Gurzuff, 1995.
- Норенков И.П. Эвристики и их комбинации в генетических методах дискретной оптимизации// Информационные технологии, 1999, № 1.
- Back T. Self-Adaptation in Genetic Algorithms. In Toward a Practice of Autonomous Systems: Proceedings of the First European Coneference on Artificial Life, 1992. pp. 263-271.
- Koza J.R. Genetic Programming II. Automatic Discovery of Reusable Programs. – London: The MIT Press, 1994
Публикации с ключевыми словами: проектирование, структурный синтез, генетический алгоритм, логистика
Публикации со словами: проектирование, структурный синтез, генетический алгоритм, логистика
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||